Categories:
Aura Context components
Definition of the main concepts and components in Aura Context
Introduction
The current document defines the key components in Aura Context:
Agent
Definition and sub-components
An agent is defined as a specific profile for accessing and using Aura Context.
This profile provides a unique layout of the information included in Aura Context, so the different fields included in the context database are shown or not or can be displayed with one specific structure or another.
An agent contains two main components: transforms and fields schema. When an agent is created, it includes by default a set of predefined transforms and fields schema that define how data is handled by the agent:
-
Component that defines the behavior of the agent when performing different operations.
It includes the default configuration for the agent using the Aura Context global data model.If developers require the modification of fields in the global data model, it must be done via transform.
-
Component that defines and validates the agent’s own data fields. It is a JSON file named
fields_schema.json, which is empty when creating an agent. It must be edited if developers want to include new fields in the global data model.
After creating an agent, developers can start using Aura Context with its default transforms.
However, if the Aura Context global data model does not fit the developer’s model, it can be modified through these two components of the agent.
Operations performed by an agent
Agents can perform three different data handling operations:
-
create_context
- Operation for the creation of a data entry in Aura Context. If a data entry already exists, it overwrites it.
- The URL has the following format:
<agent_name>/create
-
upsert_context
- Operation for the modification of a data entry in Aura Context. Depending on the existing data, this operation works to update or insert data.
- The URL has the following format:
<agent_name>/upsert
-
fetch_context
- Operation for data recovery in Aura Context.
- The URL has the following format:
<agent_name>/fetch - There are three different procedures for data fetching:
- Retrieving data using a correlator (
corrIdfield in the Aura Context global data model) - Retrieving data with user and date
- Retrieving user’s N latest data
- Retrieving data using a correlator (
These endpoints are fixed, but the user can configure how each endpoint is summoned.
Transform
Definition
In Aura Context Framework, a transform is a component that defines the behavior of an agent for the performance of different operations.
It allows the adaptation of data provided by a user into data compatible with the Aura Context data model. The transform defines the request to the API, so every agent can decide how to send data by defining the appropriate transforms.
When a developer wants to use Aura Context, she is provided with a default set of transforms, that correspond to the format suitable with the Aura Context global data model:
Find here Aura Context default transforms.
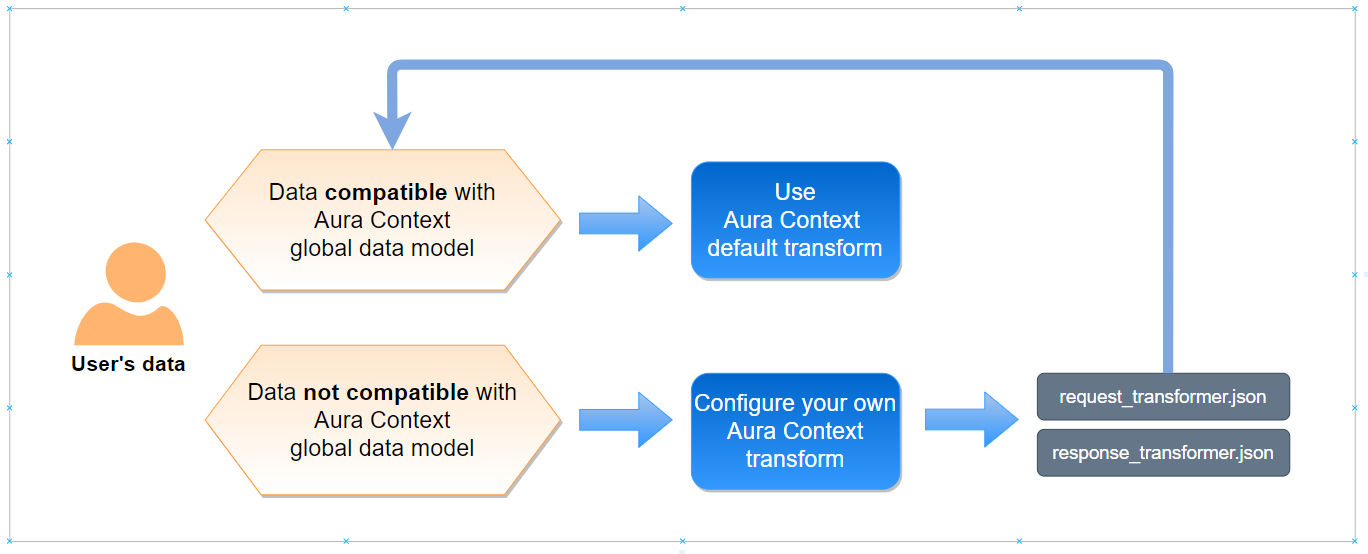
-
If the user’s data is compatible with the global data model, the developer can use the default transforms and start working with Aura Context. This situation corresponds to the API specifications set in the swagger.
-
However, if the developer requires the conversion of data with specific format into data compatible with the Aura Context global data model, he must configure his own transform. In this situation, API specifications will change. This provides a great flexibility to Aura Context, so every developer can upload his own data (in different formats or with different fields) to the Context database and the homogeneity of the uploaded data is guaranteed.
The following examples show a practical use of a transform:
-
Scenario A
- Agent bot generates data A (integer).
- Data must be stored in the context database as a string.
- The developer converts data A from integer to string via transform.
-
Scenario B
- Agent NLP has a field named “applicationId_2”
- This field is named as “applicationId” in the context database
- The developer converts the name of this field to be compatible with the context database via transform.
Files
Each transform includes two different files:
request_transformer.json:
This file allows sending free-formatted fields to be included in Aura Context through the API. Data will be transformed later on, so the resulting data is suitable with the Aura Context global data model.
The file includes the data/metadata in the request from Aura Context API:- “data” corresponds to the request body
- “metadata” corresponds with the request header
response_transformer.json:
This file allows transforming the result data from a specific operation, which fits with the context global data model, into data suitable with the input component.
The file includes the data/metadata in the response from Aura Context API:- “data” corresponds to the response body
- “metadata” corresponds with the response header
Each type of operation performed by the agent must include these two files. Therefore, the following combination of operations and files will be generated:
[working_directory]/agents/transformations/[agent_name]/create_context/request_transformer.json
[working_directory]/agents/transformations/[agent_name]/create_context/response_transformer.json
[working_directory]/agents/transformations/[agent_name]/fetch_context/request_transformer.json
[working_directory]/agents/transformations/[agent_name]/fetch_context/response_transformer.json
[working_directory]/agents/transformations/[agent_name]/upsert_context/request_transformer.json
[working_directory]/agents/transformations/[agent_name]/upsert_context/response_transformer.json
[working_directory]/agents/fields_schemas/[agent_name]/fields_schema.json
Types of Aura Context Transforms
Depending on the goal to be achieved with the transformation of the agent, there are three different types of Aura Context transforms: inferred / injected / imported. All of them has certain mandatory files:
Imported transform
This transform allows reusing common content from other transforms. The transform is imported if it is loaded from a JSON file.
Mandatory fields for this transform are included in the tables of the section fields of Aura Context transforms.
An example is shown below:
[
{
"t_type": "imported",
"relative_file_path": "../../transformer.json"
}
]
Injected transform
This transform is used to enter a forced value from the transform itself, through the o_value field. It is used when you need to load a value that is not found in the origin data or in metadata.
Mandatory fields for this transform are included in the tables of the section fields of Aura Context transforms.
An example is shown below:
[
{
"t_type": "injected",
"a_trans": [],
"o_value": "100",
"o_basic_type": "str",
"o_collection_type": "simple",
"d_path": "metadata.database.field1",
"d_basic_type": "str",
"d_collection_type": "simple",
"required": true,
"o_nullable": false,
"d_nullable": false
}
]
The output of this transform is:
metadata = {
'database': {
'field1': '100'
}
}
The field d_path is used to define the new field name, and o_value corresponds to the origin value.
Inferred transform
This transform is used to get the value from data/metadata sent in the request and transform it. For example, if the initial data is:
data = {
'information': {
'name': 'test',
}
}
And it is required to change the field path information by info, the following transform can be used:
[
{
't_type': 'inferred',
'a_trans': [],
'o_path': 'data.information.name',
'o_basic_type': 'str',
'o_collection_type': 'simple',
'd_path': 'data.info.name',
'd_basic_type': 'str',
'd_collection_type': 'simple',
'required': True,
'o_nullable': False,
'd_nullable': False
}
]
The results will be:
data = {
'info': {
'name': 'test',
}
}
The field d_path is used to define the new destination field name.
Mandatory fields for this transform are included in the tables of the section fields of Aura Context transforms.
Fields of Aura Context transforms
The definition of a transform includes several mandatory fields, depending on the transform type:
- Fields beginning with
o_: data corresponding to the transform input (origin) - Fields beginning with
d_: data corresponding to the transform output (destination)
Fields in Aura Context transforms
The following table shows the existing fields in Aura Context transforms. They can be mandatory or optional depending on the type of transform.
| Field | Description |
|---|---|
t_type |
Field that indicates the transform type (imported, injected or inferred). |
relative_file_path |
Path that indicates the location of the origin JSON file with the transforms. This file needs to be included in the agent. |
a_trans |
It indicates an additional transform and can be a list composed of the following elements: to_str, to_int, to_float, uniques, to_list, sum, average, from_json, to_json, min, max, round, round_floor or round_ceil. |
o_value |
Field value. |
o_path |
Origin field name. It must be a string formed from ASCII letters, numbers, ‘.’, ‘@’, ‘_’ and ‘-’ |
o_basic_type |
Field data type. It can be str, bool, float, int, nested or date |
nested_transformations |
It indicates a nested transform. It is mandatory if o_basic_type or d_basic_type is nested |
o_collection_type |
It indicates whether the field is a collection or a simple string. It can be list or simple |
d_basic_type |
Destination field data type in the JSON file. It can be str, bool, float, int, nested or date |
d_collection_type |
It indicates whether the field is a collection or a simple string. It can be list or simple |
d_path |
Destination field name. It must be a string formed from ASCII letters, numbers, ‘.’, ‘@’, ‘_’ |
required |
Boolean field (true / false) |
o_nullable |
It indicates that the field can be nullable before transformation (origin). It is a boolean field (true / false) |
d_nullable |
Mandatory field in injected and inferred transforms. It indicates that the field can be nullable after transformation (destination). It is a boolean field (true / false) |
The table below summarizes the mandatory fields ( ) for each type of transform:
| Fields | Imported transform | Injected transform | Inferred transform |
|---|---|---|---|
t_type |
|||
relative_file_path |
.. | .. | |
a_trans |
.. | ||
o_value |
.. | .. | |
vo_path |
.. | .. | |
o_basic_type |
.. | ||
nested_transformations |
.. | If o_basic_type or d_basic_type is nested |
if o_basic_type or d_basic_type is nested |
o_collection_type |
.. | ||
d_basic_type |
.. | ||
d_collection_type |
.. | ||
d_path |
.. | ||
required |
.. | ||
o_nullable |
.. | ||
d_nullable |
.. |
Additional Aura Context transforms
Aura Context also allow certain additional transforms that can be applied to the fields. They are indicated in the field a_trans and applied in the order they have been defined. The output of a transform is the input to the following one.
They are listed below:
to_str: It converts the field to a string.
For example: 2 –> “2”, [“hello”] –> “[“hello”]”to_int: It converts the field to an integer.
For example: “2” –> 2, 3.2 –> 3to_float: It converts the field to an integer.
For example: “2,6” –> 2.6, 3 –> 3.0uniques: It receives a list of strings and remove duplicate items.
For example: [“hello”, “hello”] -> [“hello”]to_list: It converts the field to a list.
For example: “hello” -> [“hello”]sum: It receives a list of integers or floats and sum the elements. It returns an integer if all elements are integer and otherwise, returns a float. In case of empty list, it returnsnone.average: It calculates the average of the elements of a list. It returns a float. In case of empty list, it returnsnone.from_json: It deserializes the field in a JSON.to_json: It converts the field in a serializable JSON.min: It gets the minimum of the elements in a list. It returns a float or an integer depending on the type of element. In case of empty list, it returnsnone.max: It gets the maximum of the elements in a list. It returns a float or an integer depending on the type of element. In case of empty list, it returnsnone.round: Round up. It returns an integer.round_floor: Round down. It returns an integer.round_ceil: Round up. It returns an integer.
It is also possible to define multiple additional transforms in the a_trans field.
For example:
{
"a_trans": ["sum", "to_int"],
}
If you have the following data:
data = [2.1, 3.0]
-
- All elements are added
-
- It converts the result into an integer. So, the result will be 5.
Data and metadata
Data availability
Aura Context works with data and metadata for every operation to be performed (create, upsert or fetch).
In order to perform these operations, it is required to know how the Aura Context API matches input data (data sent via API) with data/metadata for Aura Context and vice versa (how internal data/metadata used by Aura Context for each operation is transformed into response data).
Currently, the three permitted operations correspond to the HTTP POST request method:
-
HTTP POSTrequest’s body and headers will be matched with the input data and metadata of the request transform respectively.- Field
data: request body - Field
metadata: request headers
- Field
-
After the execution of the corresponding operation, the data/metadata in the response transform will be matched with the HTTP body and headers respectively:
- Field
data: response body - Field
metadata: response headers
- Field
The following figure shows the match between HTTP request/response and Aura Context data/metadata:
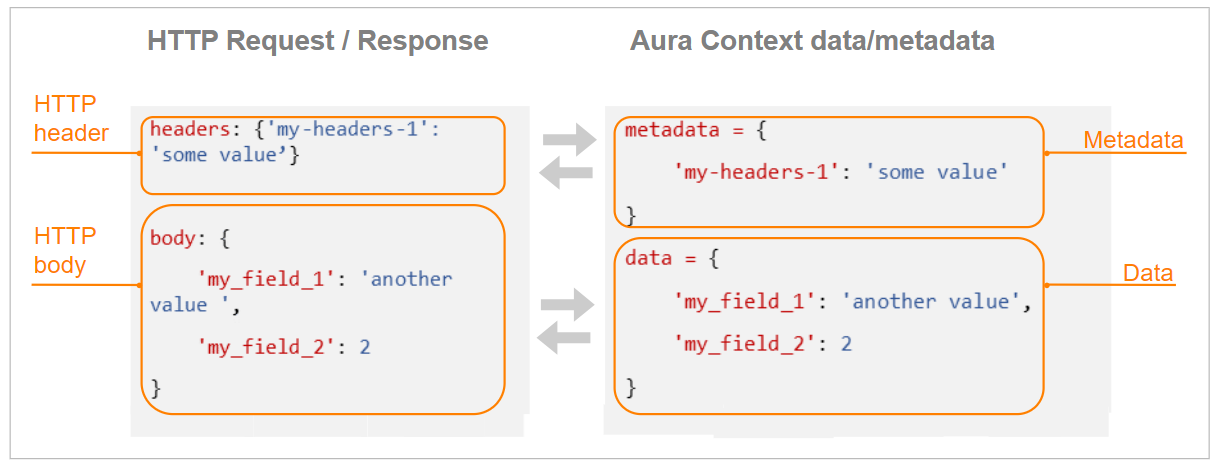
As an example, if the following request is sent:
headers: {'my-headers-1': 'some value'}
body: {
'my_field_1': 'another value',
'my_field_2': 2
}
Then, the following data and metadata will be available to be used in the request transforms:
data = {
'my_field_1': 'another value',
'my_field_2': 2
}
metadata = {
'my-headers-1': 'some value'
}
Therefore, a transform containing the following input fields can be generated:
{
'o_path': 'data.my_field_1',
'o_collection_type': 'simple',
'o_basic_type': 'str'
}
Apart from these general considerations for the use of data and metadata in Aura Context, each specific operation (create, upsert, fetch) require certain data/metadata for the request and for the response. They are described in the following sections.
Data and metadata in create and upsert operations
Remember that this section is useful just for generating your own transforms, as the default ones already include this content
request_transformer.json
- Data and metadata required for the create/upsert operations must be transformed in a specific way so as to be a valid input for these operations:
- Data: Document to be inserted in the context database, following the requirements of the global data model. Therefore, each field must match with the fields of the global database (column “Name in database”).
- Metadata: Automatically generated.
response_transformer.json
- Once data is created/modified in the context database, these two operations generates another data/metadata with the result of the corresponding operation.
- These data and metadata can be used as input fields for the
response_transformer.jsonfile, with the following mandatory fields:- Data:
results: List includingtrue/falsevalue for the result of the process of inserting/modifying data (upsert operation)
- Metadata:
db_execution_time: Duration of the operation execution in the database
- Data:
An example is shown below:
{
'o_path': 'metadata.db_execution_time',
'o_collection_type': 'simple',
'o_basic_type': 'float',
'd_path': 'data.execution_time',
'o_collection_type': 'simple',
'o_basic_type': 'float'
}
In this example, the body of the response to the request includes a new field execution_time, with the value of the operation duration.
Data and metadata in fetch operation
The fetch operation includes different procedures, each of them requiring different data and metadata depending on the type of query to the database.
The content of data and metadata on each operation is described in the following sections.
Common data and metadata
Common data and metadata for the three different procedures in the request_transformer.json file.
- Data
projection(optional): this field filters specific fields from each document fetched from the context database
- Metadata
page_size(optional): number of documents to be retrieved from the context database (applicable in case of queries including page numbering)page(optional): page to be retrieved from the context database (applicable in case of queries including page numbering)
Fetch by correlator
Apart from the common data and metadata, the following mandatory data/metadata must be included in the request_transformer.json:
- Metadata
corr: correlator ID to be fetched from the context database, together with theaura_id_globalparameter.
Fetch by user’s N latest data
Apart from the common data and metadata, the following mandatory data/metadata must be included in the request_transformer.json:
- Data
last_n: number of documents to be retrieved from the context database
Fetch by date range
Apart from the common data and metadata, the following mandatory data/metadata must be included in the request_transformer.json:
- Data
start_date: starting date of the date rangeend_date: ending date of the date range
When the fetch operation is executed, the data and metadata from the response, which follow the format from the global data model, can be transformed to fit with the user’s data model in the response_transformer.json file. In this transform, only data from the response documents can be modified, the remaining data are provided back by default (this is fully specified in the Aura Context swagger).
Fields schema
Definition
The fields schema is the second component of an Aura Context agent. It is used for the definition of new fields on the Aura Context global data model if it is required by the developer.
When an agent is created, it includes the empty JSON file fields_schema.json.
Find here Aura Context default fields schema.
If the developer requires the generation of a new field in the global data model to be adapted to his own data, he must modify the fields schema:
- Edition of the
fields_schema.jsonto include the necessary modifications. - Definition of the modifications in the transform: Once the fields schema file has been modified, these variations must also be reflected on the agent’s transform.
Fields schema format
The file fields_schema.json is a dictionary of dictionaries that includes the different types of fields that must be used in the agent’s transform.
These fields must have the following format:
<data | metadata>. <agent_name> @ <field_name>
Where:
<data | metadata>: origin of the field (data or metadata)<agent_name>: name of the agent<field_name>: name of the field
Each new field is characterized by two main parameters:
basic_type: it can bestr,bool,int,float,nestedanddate.collection_type: it can be of typesimpleorlist.
It is important to bear in mind that new fields in the Aura Context global data model must be created in a new table, as it is not possible to add a field to an existing table such as Application, Environment, etc.