This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Aura dashboards
Aura dashboards
Discover the dashboards that can be generated through the different tools used for Aura monitoring in order to track and analyze data
Introduction
Dashboards are reporting tools that aggregate and display metrics and key indicators, so they can be examined at a glance by all possible audiences.
These dashboards allow data interpretation and provide an overall view for the evaluation of Aura’s performance, thus improving decision-making. Each component counts on a dashboard to show its current behavior and there is a single dashboard for an Aura overview.
There are two types of dashboards for Aura metrics (Prometheus) that are generated in Grafana:
1 - Aura system dashboards
Aura system dashboards
Grafana dashboards with metrics related to the performance of Aura system
Introduction
Currently, these are the available Aura system dashboards in Grafana based on metrics stored in Prometheus:
1.1 - Alertmanager dashboard
Alertmanager dashboard
Information provided by Alertmanager dashboards
Panels
Received alerts rate
It shows a time series with the received alerts rate aggregated by one minute.
The x-axis shows the time series and the y-axis shows received alerts rate.
The queries used to get the panel information are:
sum(rate(prometheus_notifications_alertmanagers_discovered[1m])) by(status)
An example of this panel is shown below:

The available metrics are defined in the following sections.
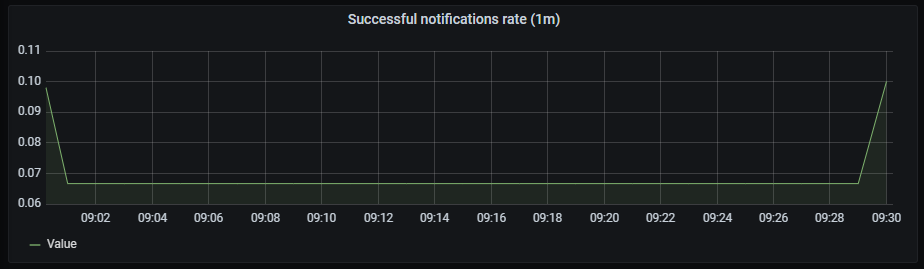
Successful notification rate
It shows a time series with the successful notifications rate aggregated by one minute.
The x-axis shows the time series and the y-axis shows the successful notifications rate.
The queries used to get the panel information are:
sum(rate(prometheus_notifications_sent_total[1m])) by(integration)
An example of this panel is shown below:
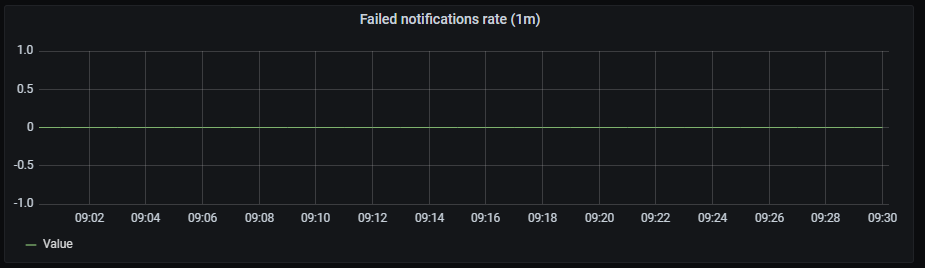
Failed notifications rate
It shows a time series with the failed notifications rate aggregated by one minute.
The x-axis shows the time series and the y-axis shows the failed notifications rate.
The queries used to get panel information are:
sum(rate(prometheus_notifications_errors_total[1m])) by(integration)
An example of this panel is shown below:
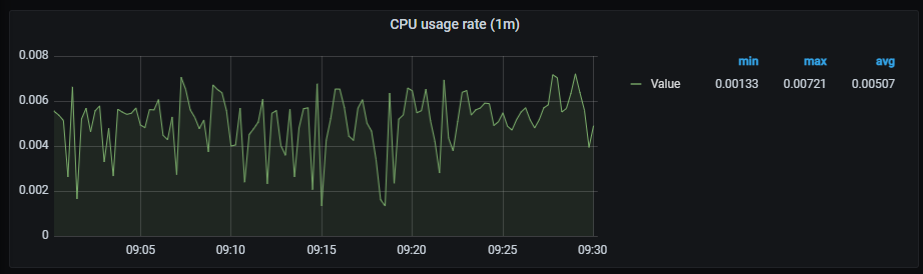
CPU usage rate
It shows a time series with the CPU usage rate aggregated by one minute. It also shows the current minimum, maximum and average cpu consumption of alertmanager.
The x-axis shows the time series and the y-axis shows the CPU usage rate.
The queries used to get panel information are:
sum(rate(container_cpu_usage_seconds_total{container="alertmanager"}[1m])) by (pod_name)
An example of this panel is shown below:
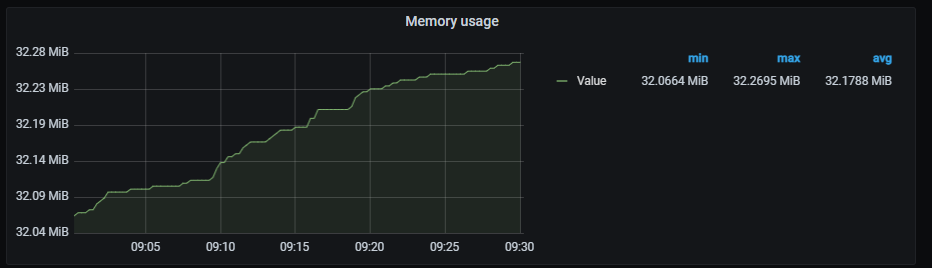
Memory usage
It shows a time series with the memory usage. It also shows the current minimum, maximum and average memory consumption of alertmanager.
The x-axis shows the time series and the y-axis shows the memory usage.
The queries used to get panel information are:
sum (container_memory_working_set_bytes{container="alertmanager"}) by (pod_name)
An example of this panel is shown below:
Pods network I/O
It shows a time series with the network I/O average aggregated by one minute. It also shows the current minimum, maximum and average network I/O.
The x-axis shows the time series and the y-axis shows the network usage.
The queries used to get panel information are:
sum (rate (container_network_receive_bytes_total{pod!="",pod=~"alertmanager.*"}[1m])) by (pod)
- sum (rate (container_network_transmit_bytes_total{pod!="",pod=~"alertmanager.*"}[1m])) by (pod)
An example of this panel is shown below:

1.2 - Elasticsearch dashboard
Elasticsearch dashboard
Information provided by Elasticsearch dashboard
Introduction
Elastic dashboard monitors multiple data, service and system related metrics.
The different graphs are shown in the following sections:
- Cluster graphs
- Shard graphs
- system graphs
- Documents graphs
- Total operations stats graphs
- Elastic search times graphs
- Caches graphs
- Thread pool graphs
- JVM garbage collection graphs
Cluster graphs
The current section includes cluster related graphs.
Health status
Code coloured indicator of cluster health.
Metrics:
((sum(elasticsearch_cluster_health_status{color="green"})*2)+sum(elasticsearch_cluster_health_status{color="yellow"}))/count(elasticsearch_index_stats_up)
Nodes
Number of nodes.
Metrics:
count(elasticsearch_index_stats_up)
Data nodes
Number of data nodes per node.
Metrics:
sum(elasticsearch_cluster_health_number_of_data_nodes{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Pending tasks
Pending tasks per node.
Metrics:
sum(elasticsearch_cluster_health_number_of_pending_tasks{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Graph visual

Shards graphs
Shards related graphs.
Active primary shards
Number of active primary shards per node.
Metrics:
sum(elasticsearch_cluster_health_active_primary_shards{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Active shards
Number of active shards per node.
Metrics:
sum(elasticsearch_cluster_health_active_shards{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Initializing shards
Number of shards initializing per node.
Metrics:
sum(elasticsearch_cluster_health_initializing_shards{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Relocating shards
Number of relocating shards per node.
Metrics:
sum(elasticsearch_cluster_health_relocating_shards{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Unassigned shards
Number of unassigned shards per node.
Metrics:
sum(elasticsearch_cluster_health_delayed_unassigned_shards{cluster="elasticsearch"})/count(elasticsearch_index_stats_up)
Graph visual

System graphs
System related graphs.
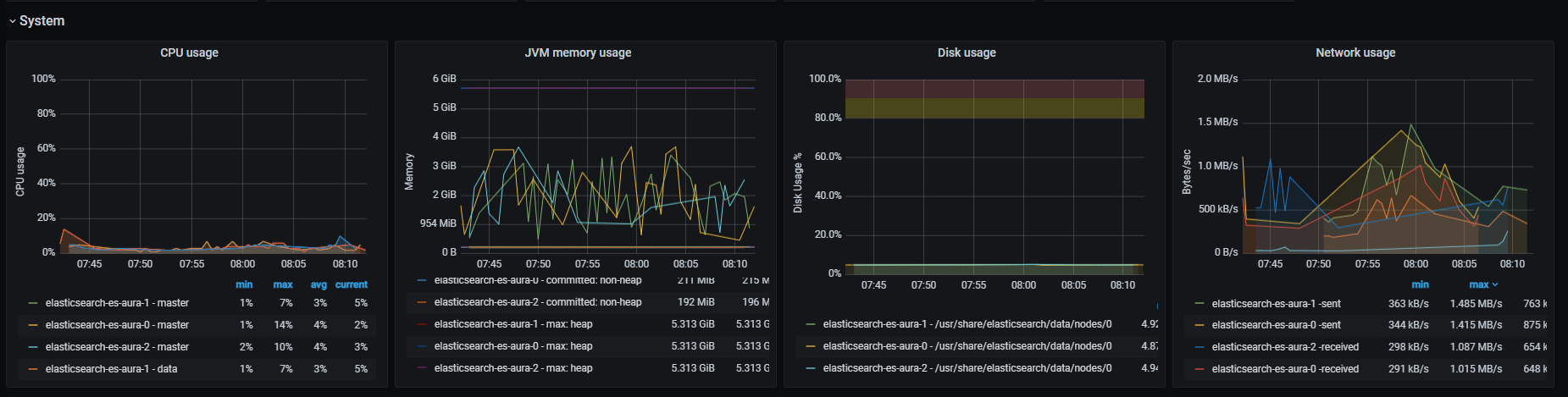
CPU usage
Percentage of used CPU on master and data nodes.
Metrics:
It includes two metrics:
elasticsearch_process_cpu_percent{cluster="elasticsearch",es_master_node="true",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
elasticsearch_process_cpu_percent{cluster="elasticsearch",es_data_node="true",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
JVM memory usage
Memory used by JVM graph in bytes.
Metrics:
It includes three metrics:
elasticsearch_jvm_memory_used_bytes{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
elasticsearch_jvm_memory_committed_bytes{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
elasticsearch_jvm_memory_max_bytes{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
Disk usage
Disk usage in bytes.
Metrics:
1-(elasticsearch_filesystem_data_available_bytes{cluster="elasticsearch"}/elasticsearch_filesystem_data_size_bytes{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"})
Network usage
Bytes rate sent and received, aggregated by one minute.
Metrics:
It includes two metrics:
irate(elasticsearch_transport_tx_size_bytes_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_transport_rx_size_bytes_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Graph visual
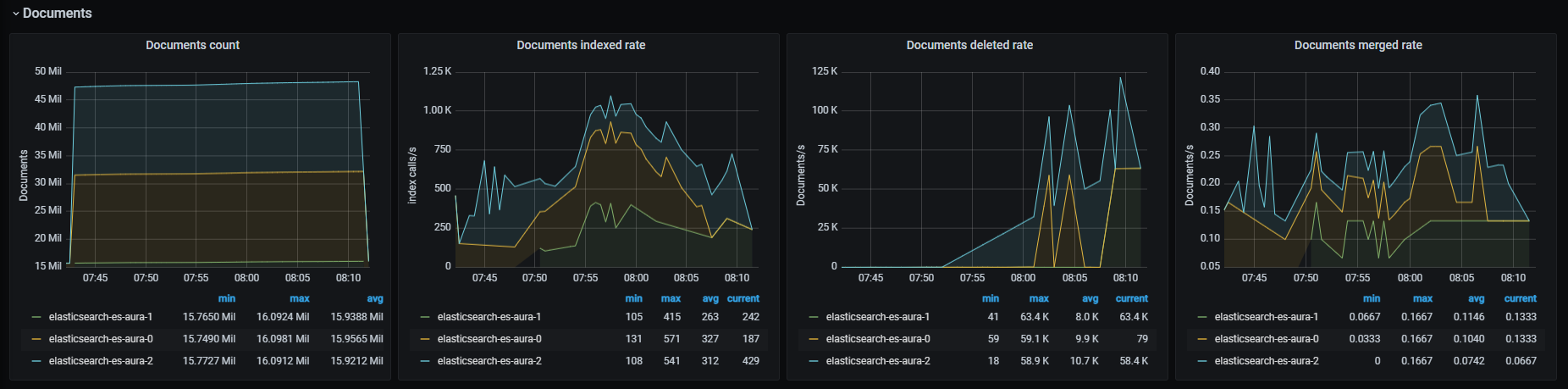
Documents graphs
Documents state related graphs.
Documents count
Number of documents in cluster.
Metrics:
elasticsearch_indices_docs{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
Documents indexed rate
Rate of indexed documents, aggregated by one minute.
Metrics:
irate(elasticsearch_indices_indexing_index_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Documents deleted rate
Rate of deleted documents, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_docs_deleted{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Documents merged rate
Rate of merged documents, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_merges_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Graph visual
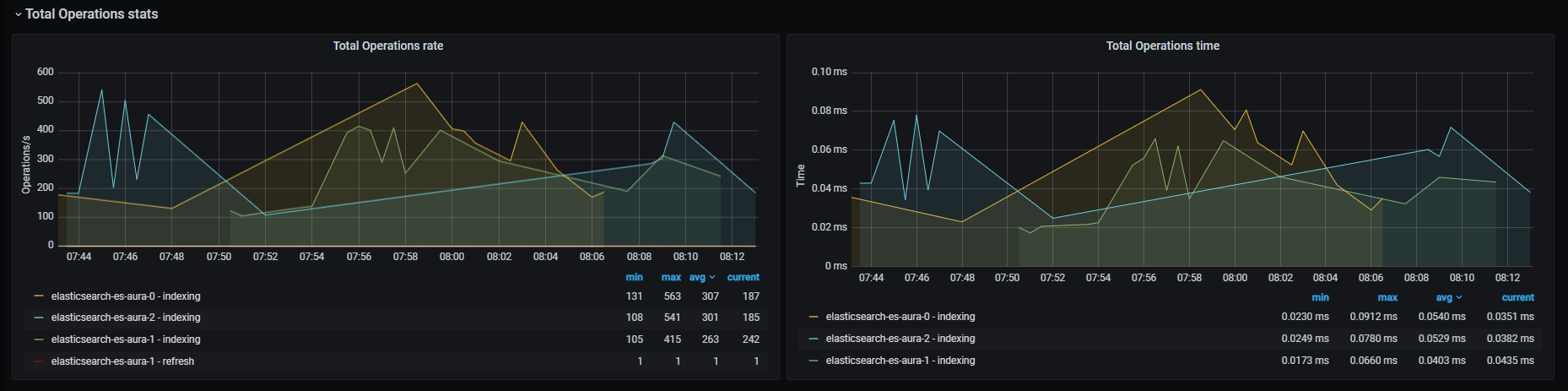
Total operations stats graphs
Data related to total operations.
Total operations rate
Total operations number rate, aggregated by one minute.
Metrics:
It includes six metrics:
irate(elasticsearch_indices_indexing_index_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_search_query_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_search_fetch_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_merges_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_refresh_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_flush_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Total operations time
Time rate for the different operations in milliseconds, aggregated by one minute.
Metrics:
It includes six metrics:
irate(elasticsearch_indices_indexing_index_time_seconds_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_search_query_time_ms_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_search_fetch_time_ms_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_merges_total_time_ms_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_refresh_total_time_ms_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
irate(elasticsearch_indices_flush_time_ms_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Graph visual
Elasticsearch times graphs
Graphs related to elapsed times of different actions.
Query time
Time rate for search query operations in seconds, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_search_query_time_seconds{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Indexing time
Time rate for indexing index operations in seconds, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_indexing_index_time_seconds_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Merging time
Time rate for merge operations in seconds, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_merges_total_time_seconds_total{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
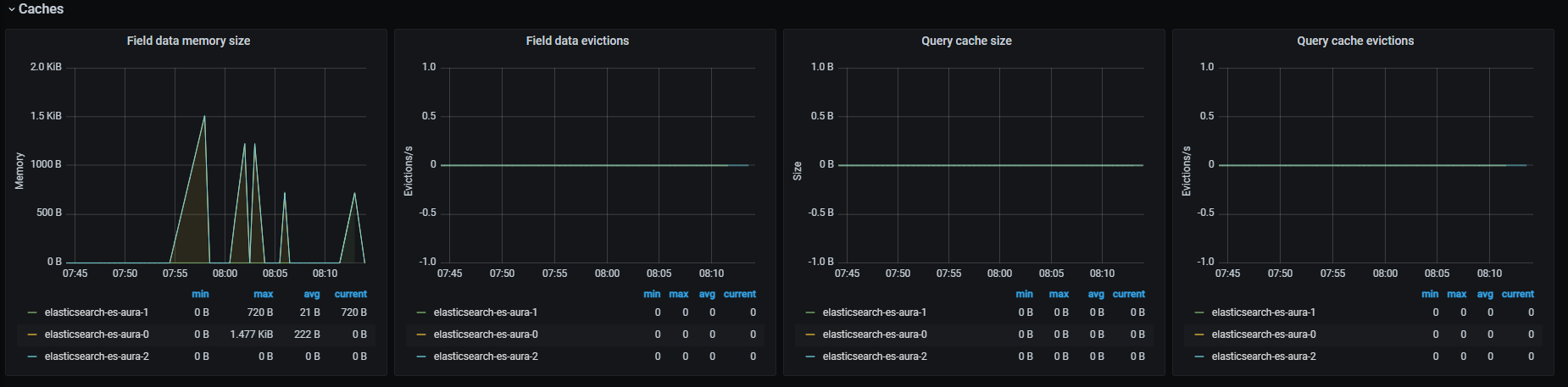
Caches graphs
Graphs related to caches metrics.
Field data memory size
Field data memory size in bytes.
Metrics:
elasticsearch_indices_fielddata_memory_size_bytes{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
Field data evictions
Rate of field data evicted, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_fielddata_evictions{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Query cache size
Bytes of memory occupied by cached queries.
Metrics:
elasticsearch_indices_query_cache_memory_size_bytes{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
Query cache evictions
Rate of queries evicted, aggregated by one minute.
Metrics:
rate(elasticsearch_indices_query_cache_evictions{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Graph visual
Thread pool graphs
Graphs related to the thread pool.
Operations rejected
Rate of rejected operations, aggregated by one minute.
Metrics:
irate(elasticsearch_thread_pool_rejected_count{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Operations queued
Rate of queued operations, aggregated by one minute.
Metrics:
elasticsearch_thread_pool_active_count{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
Threads active
Number of active threads.
Metrics:
elasticsearch_thread_pool_active_count{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}
Operations completed
Shows rate of completed operations, aggregated by one minute
Metrics:
irate(elasticsearch_thread_pool_completed_count{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Graph visual
JVM Garbage collection graphs
Graphs related to JVM garbage collector activity.
GC count
Rate of GC count, aggregated by one minute.
Metrics:
rate(elasticsearch_jvm_gc_collection_seconds_count{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
GC time
Rate of GC execution time, aggregated by one minute.
Metrics:
rate(elasticsearch_jvm_gc_collection_seconds_count{cluster="elasticsearch",name=~"(elasticsearch-es-aura-0|elasticsearch-es-aura-1|elasticsearch-es-aura-2)"}[1m])
Graph visual
1.3 - Fluent bit dashboard
Fluent bit dashboard
Information provided by Fluent bit dashboard
Introduction
Fluent bit dashboard monitors system metrics related to fluent bit.
The available metrics are defined in the following sections.
Input bytes rate, aggregated by one minute.
Metrics:
rate(fluentbit_input_bytes_total[1m])
Graph visual
Output bytes
Output bytes rate, aggregated by one minute.
Metrics:
rate(fluentbit_output_proc_bytes_total[1m])
Graph visual

Retries/fails
Rate of retries and fails, aggregated by one minute
Metrics:
It includes two metrics:
rate(fluentbit_output_retries_total[1m])
rate(fluentbit_output_retries_failed_total[1m])
Graph visual
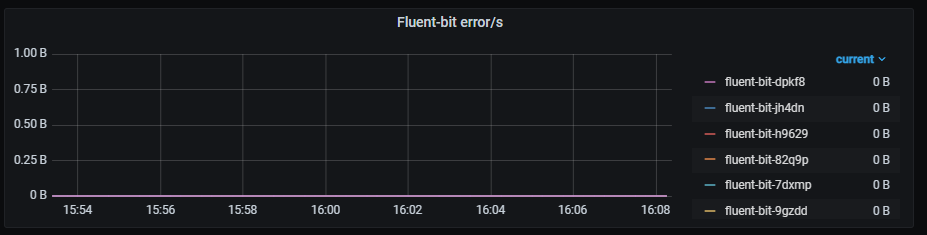
Errors
Rate of output errors, aggregated by one minute.
Metrics:
rate(fluentbit_output_errors_total[1m])
Graph visual
1.4 - Kubernetes cluster monitoring dashboard
Kubernetes cluster monitoring dashboard
Information provided by Kubernetes cluster monitoring dashboard
Introduction
Kubernetes cluster monitoring dashboard monitors multiple systems and networks related data from Kubernetes clusters.
The available metrics are defined in the following sections.
Network I/O pressure graph
Rate of total received/sent data on all cluster containers, in bytes and aggregated by one minute.
Metrics:
It includes two metrics:
sum (rate (container_network_receive_bytes_total{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m]))
- Sent bytes (negative value)
- sum (rate (container_network_transmit_bytes_total{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m]))
Graph visual

Total usage
Graphs with different system parameters usage.
Cluster memory usage
It is composed by three graphs:
- Memory usage, showing percentage of used memory
- Used, showing used memory
- Total, showing total memory
Metrics:
It includes three metrics:
sum (container_memory_working_set_bytes{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) /
sum (machine_memory_bytes{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) * 100
sum (container_memory_working_set_bytes{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"})
sum (machine_memory_bytes{kubernetes_io_hostname=~"^.*$",agentpool=~".*"})
Cluster CPU usage
It is composed by three graphs:
- CPU usage, showing percentage of used CPU cores, aggregated by one minute
- Used, showing used CPU cores, aggregated by one minute
- Total, showing total CPU cores
Metrics:
It includes three metrics:
sum (rate (container_cpu_usage_seconds_total{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) /
sum (machine_cpu_cores{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) * 100
sum (rate (container_cpu_usage_seconds_total{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m]))
sum (machine_cpu_cores{kubernetes_io_hostname=~"^.*$",agentpool=~".*"})
Cluster filesystem usage
It is composed by three graphs:
- Filesystem usage, showing percentage of used filesystem space
- Used, showing used filesystem space
- Total, showing total filesystem space
Metrics:
It includes three metrics:
sum (container_fs_usage_bytes{device=~"^/dev/.*$",id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) /
sum (container_fs_limit_bytes{device=~"^/dev/.*$",id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) * 100
sum (container_fs_usage_bytes{device=~"^/dev/.*$",id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"})
sum (container_fs_limit_bytes{device=~"^/dev/.*$",id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"})
Graph visual

Pods CPU usage
CPU usage rate, classified by pod and aggregated by one minute.
Metrics:
sum (rate (container_cpu_usage_seconds_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (pod_name)
Graph visual

Containers CPU usage
CPU usage rate, classified by container and aggregated by one minute.
Metrics:
It includes two metrics:
sum (rate (container_cpu_usage_seconds_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (pod_name)
- Containers without “k8s_”
sum (rate (container_cpu_usage_seconds_total{image!="",name!~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname, name, image)
Graph visual

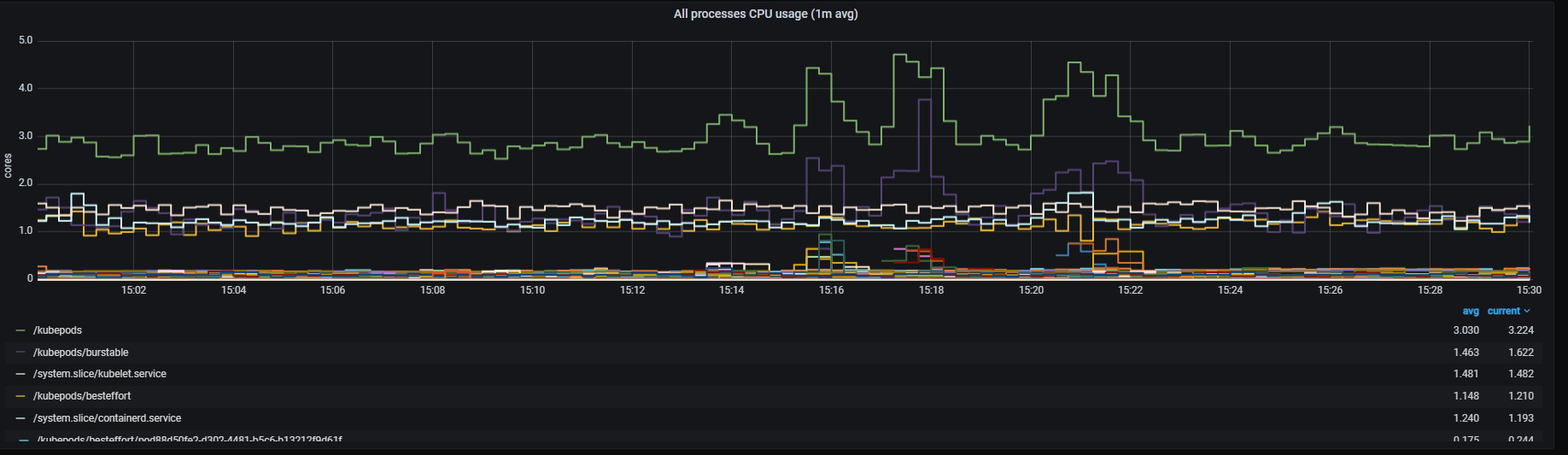
All processes CPU usage
Total CPU usage rate, aggregated by one minute.
Metrics:
sum (rate (container_cpu_usage_seconds_total{id!="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (id)
Graph visual
Pods memory usage
Memory usage, classified by pod.
Metrics:
sum (container_memory_working_set_bytes{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (pod_name)
Graph visual

Containers memory usage
Memory usage, classified by container.
Metrics:
It includes two metrics:
sum (container_memory_working_set_bytes{image!="",name=~"^k8s_.*",container_name!="POD",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (container_name, pod_name)
- Containers without “k8s_”
sum (container_memory_working_set_bytes{image!="",name!~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (kubernetes_io_hostname, name, image)
Graph visual

All processes memory usage
Total memory usage rate.
Metrics:
sum (container_memory_working_set_bytes{pod_name!="",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (pod_name)
Graph visual
Pods network I/O
Total network received/sent usage rate, classified by pod and aggregated by one minute.
Metrics:
sum (rate (container_network_receive_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (pod_name)
- sum (rate (container_network_transmit_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (pod_name)
Graph visual

Containers network I/O
Total network received/sent usage rate, classified by container and aggregated by one minute.
Metrics:
- Received bytes, containers with “k8s_”
sum (rate (container_network_receive_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (container_name, pod_name)
- Sent bytes, containers with “k8s_”
- sum (rate (container_network_transmit_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (container_name, pod_name)
- Received bytes, containers without “k8s_”
sum (rate (container_network_receive_bytes_total{image!="",name!~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname, name, image)
- Sent bytes, containers without “k8s_”
- sum (rate (container_network_transmit_bytes_total{image!="",name!~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname, name, image)
Graph visual

All processes network I/O
Total network received/sent usage rate, aggregated by one minute.
Metrics:
sum (rate (container_network_receive_bytes_total{pod_name!="",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (pod_name)
- sum (rate (container_network_transmit_bytes_total{pod_name!="",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (pod_name)
Graph visual
Pods disk I/O
Total disk reads/writes rate, classified by pod and aggregated by one minute.
Metrics:
- Read bytes, pods without device
sum(rate(container_fs_reads_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device!=""}[1m])) by (pod_name)
- Written bytes, pods without device
sum(rate(container_fs_writes_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device!=""}[1m])) by (pod_name)
- Read bytes, pods with device
sum(rate(container_fs_reads_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device=""}[1m])) by (pod_name)
- Written bytes, pods with device
sum(rate(container_fs_writes_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device=""}[1m])) by (pod_name)
Graph visual

Containers disk I/O
Total disk reads/writes rate, classified by container and aggregated by one minute.
Metrics:
- Read bytes, containers without device
sum(rate(container_fs_reads_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device!=""}[1m])) by (container_name, pod_name)
- Written bytes, containers without device
sum(rate(container_fs_writes_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device!=""}[1m])) by (container_name, pod_name)
- Read bytes, containers with device
sum(rate(container_fs_reads_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device=""}[1m])) by (container_name, pod_name)
- Written bytes, containers with device
sum(rate(container_fs_writes_bytes_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*", device=""}[1m])) by (container_name, pod_name)
- Read bytes, containers without “k8s_”
sum(rate(container_fs_reads_bytes_total{image!="",name!~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname, name, image)
- Written bytes, containerswithout “k8s_”
sum(rate(container_fs_writes_bytes_total{image!="",name!~"^k8s_.*",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname, name, image)
Graph visual

1.5 - Kubernetes cron and batch job monitoring dashboard
Kubernetes cron and batch job monitoring dashboard
Information provided by cron and batch job monitoring dashboard
Introduction
Kubernetes cron and batch job monitoring dashboard monitors success/fail rates for cron/batch jobs.
The available metrics are defined in the following sections.
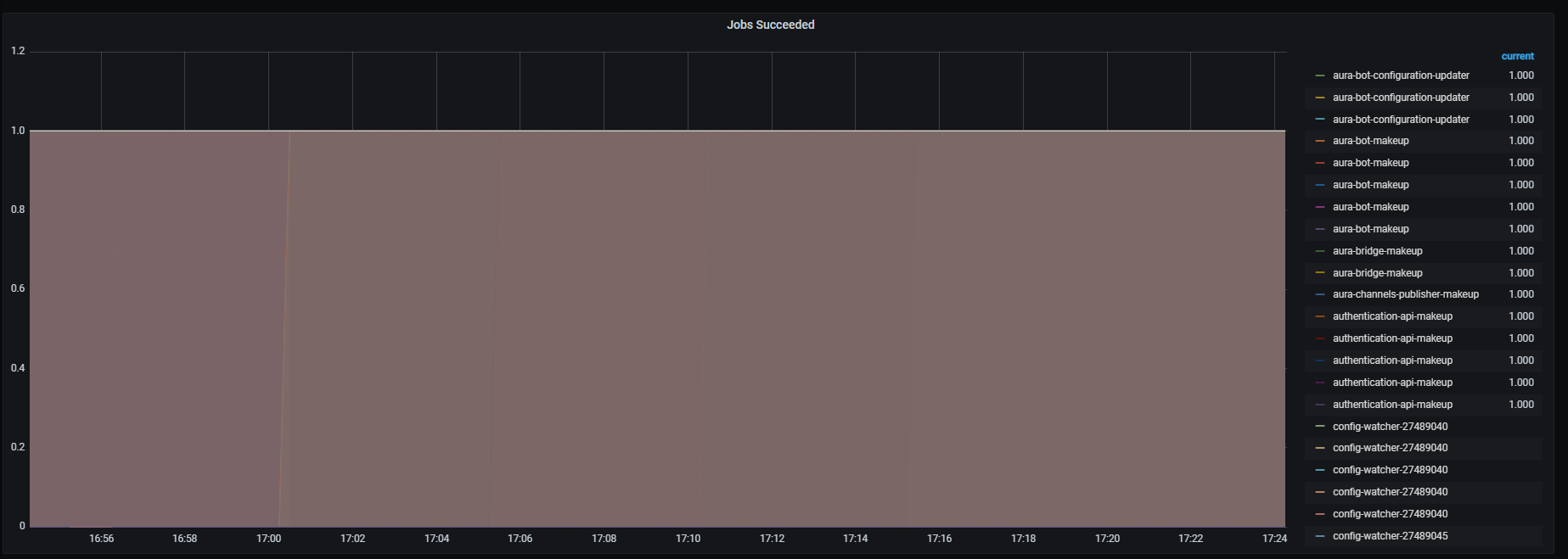
Jobs succeeded
Successfully executed jobs.
Metrics:
kube_job_status_succeeded
Graph visual
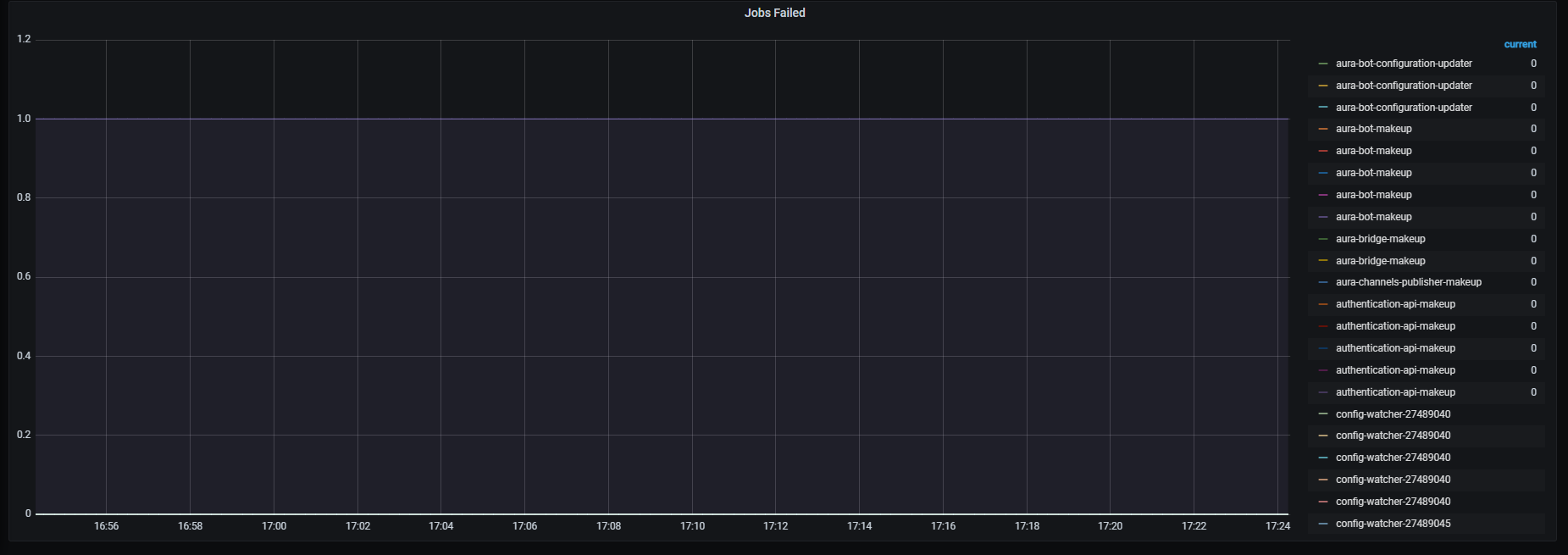
Jobs failed
Failed job executions.
Metrics:
Graph visual
1.6 - Kubernetes nodes dashboard
Kubernetes nodes dashboard
Information provided by Kubernetes nodes dashboard
Introduction
Kubernetes nodes dashboard monitors nodes general system status.
The available metrics are defined in the following sections.
CPU usage
CPU usage percent rate, aggregated by one minute.
Metrics:
sum (rate (container_cpu_usage_seconds_total{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname) / sum (machine_cpu_cores{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (kubernetes_io_hostname) * 100
Graph visual

Memory usage
Memory usage percentage.
Metrics:
sum (container_memory_working_set_bytes{id="/", kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (kubernetes_io_hostname) / sum (machine_memory_bytes{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (kubernetes_io_hostname) * 100
Graph visual

Disk I/O
Disk read/written data in bytes.
Metrics:
It includes two metrics:
sum (container_fs_reads_bytes_total{id="/", kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (kubernetes_io_hostname)
sum (container_fs_writes_bytes_total{id="/", kubernetes_io_hostname=~"^.*$",agentpool=~".*"}) by (kubernetes_io_hostname)
Graph visual

Network I/O
Network received/sent data in bytes, aggregated by one minute.
Metrics:
It includes two metrics:
sum (rate (container_network_receive_bytes_total{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname)
- sum (rate (container_network_transmit_bytes_total{id="/",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}[1m])) by (kubernetes_io_hostname)
Graph visual

1.7 - Kubernetes services dashboard
Kubernetes services dashboard
Information provided by Kubernetes services dashboard
Introduction
Kubernetes services dashboard monitors system metrics related to services/pods.
The available metrics are defined in the following sections.
Service CPU usage
Services cpu usage rate, aggregated by one minute
Metrics:
sum(rate(container_cpu_usage_seconds_total{container!="",container=~".*"}[1m])) by (container)
Graph visual

Pods CPU usage
Pods CPU usage rate, aggregated by one minute.
Metrics:
It includes two metrics:
- CPU usage by pod and container
sum (rate (container_cpu_usage_seconds_total{container!="",container=~".*"}[1m])) by (container, pod)
- CPU usage by container and instance
sum (rate (container_cpu_usage_seconds_total{container!="",container=~".*"}[1m])) by (instance, container)
Graph visual

Service memory usage
Service memory usage in bytes.
Metrics:
sum (container_memory_working_set_bytes{container!="",container=~".*"}) by (container)
Graph visual

Pods memory usage
Pods memory usage in bytes, and memory usage rate aggregated by one minute
Metrics:
It includes four metrics:
- memory usage classified by pod and container
sum (container_memory_working_set_bytes{container!="",container=~".*"}) by (container, pod)
- memory usage classified by container, image and instance
sum (rate (container_cpu_usage_seconds_total{container!="",container=~".*"}[1m])) by (instance, container)
- memory usage rate, classified by pod and container, and aggregated by one minute
sum (rate (container_memory_working_set_bytes{container!="",container=~".*"}[1m])) by (container, pod)
- memory usage rate, classified by instance and container, and aggregated by one minute
sum (rate (container_memory_working_set_bytes{container!="",container=~".*"}[1m])) by (instance, container)
Graph visual

Service network I/O
Network received/sent data rate, aggregated by one minute
Metrics:
It includes two metrics:
sum (container_memory_working_set_bytes{container!="",container=~".*"}) by (container)
- sum (rate (container_network_transmit_bytes_total{pod!="",pod=~".*.*"}[1m])) by (pod)
Graph visual

Pods network I/O
Pods received/sent data rate in bytes, aggregated by one minute.
Metrics:
It includes four metrics:
- Received bytes classified by pod
sum (rate (container_network_receive_bytes_total{pod!="",pod=~".*.*"}[1m])) by (name, pod)
- Sent bytes classified by pod
- sum (rate (container_network_transmit_bytes_total{pod!="",pod=~".*.*"}[1m])) by (container, pod)
- Received bytes classified by container and instance
sum (rate (container_network_receive_bytes_total{pod!="",pod=~".*.*"}[1m])) by (instance, container, image)
- Send bytes classified by container and instance
- sum (rate (container_network_transmit_bytes_total{pod!="",pod=~".*.*"}[1m])) by (instance, container, image)
Graph visual

1.8 - Kubernetes storage monitoring dashboard
Kubernetes storage monitoring dashboard
Information provided by Kubernetes storage monitoring dashboard
Introduction
Kubernetes storage monitoring dashboard monitors storage related metrics.
The available metrics are defined in the following sections.
Used space
Kubelets volumes and container filesystems data usage in bytes.
Metrics:
It includes two metrics:
- Kubelet volumes used bytes
kubelet_volume_stats_used_bytes{kubernetes_io_hostname=~"^.*$",agentpool=~".*"}
- Container filesystem usage in bytes
container_fs_usage_bytes{image!="",kubernetes_io_hostname=~"^.*$",agentpool=~".*"}
Graph visual

PVC used space %
PersistentVolumeClaim used space percent.
Metrics:
(kubelet_volume_stats_used_bytes{kubernetes_io_hostname=~"^.*$",agentpool=~".*",persistentvolumeclaim=~"(data-prometheus-0|data-prometheus-1|data-prometheus-2|datadir-mongodb-0|datadir-mongodb-1|datadir-mongodb-2|elasticsearch-data-elasticsearch-es-aura-0|elasticsearch-data-elasticsearch-es-aura-1|elasticsearch-data-elasticsearch-es-aura-2|grafana-grafana-0|redis-data-redis-0|redis-data-redis-1|redis-data-redis-2|store-thanos-store-gateway-0|store-thanos-store-gateway-1)"} / kubelet_volume_stats_capacity_bytes{kubernetes_io_hostname=~"^.*$",agentpool=~".*",persistentvolumeclaim=~"(data-prometheus-0|data-prometheus-1|data-prometheus-2|datadir-mongodb-0|datadir-mongodb-1|datadir-mongodb-2|elasticsearch-data-elasticsearch-es-aura-0|elasticsearch-data-elasticsearch-es-aura-1|elasticsearch-data-elasticsearch-es-aura-2|grafana-grafana-0|redis-data-redis-0|redis-data-redis-1|redis-data-redis-2|store-thanos-store-gateway-0|store-thanos-store-gateway-1)"})
Graph visual

Local used space %
Containers assigned space usage percentage.
Metrics:
(container_fs_usage_bytes{image!="",kubernetes_io_hostname=~"^.*$",agentpool=~".*"} / container_fs_limit_bytes{image!="",kubernetes_io_hostname=~"^.*$",agentpool=~".*"})
Graph visual

Used inodes
Kubelet PersistentVolumeClaim volumes total used inodes.
Metrics:
kubelet_volume_stats_inodes_used{kubernetes_io_hostname=~"^.*$",agentpool=~".*",persistentvolumeclaim=~"(data-prometheus-0|data-prometheus-1|data-prometheus-2|datadir-mongodb-0|datadir-mongodb-1|datadir-mongodb-2|elasticsearch-data-elasticsearch-es-aura-0|elasticsearch-data-elasticsearch-es-aura-1|elasticsearch-data-elasticsearch-es-aura-2|grafana-grafana-0|redis-data-redis-0|redis-data-redis-1|redis-data-redis-2|store-thanos-store-gateway-0|store-thanos-store-gateway-1)"}
Graph visual

Used inodes
Kubelet PersistentVolumeClaim volumes total used inodes.
Metrics:
kubelet_volume_stats_inodes_used{kubernetes_io_hostname=~"^.*$",agentpool=~".*",persistentvolumeclaim=~"(data-prometheus-0|data-prometheus-1|data-prometheus-2|datadir-mongodb-0|datadir-mongodb-1|datadir-mongodb-2|elasticsearch-data-elasticsearch-es-aura-0|elasticsearch-data-elasticsearch-es-aura-1|elasticsearch-data-elasticsearch-es-aura-2|grafana-grafana-0|redis-data-redis-0|redis-data-redis-1|redis-data-redis-2|store-thanos-store-gateway-0|store-thanos-store-gateway-1)"}
Graph visual
PVC used inodes %
Kubelet PersistentVolumeClaim volumes inodes usage percentage.
Metrics:
(kubelet_volume_stats_inodes_used{kubernetes_io_hostname=~"^.*$",agentpool=~".*",persistentvolumeclaim=~"(data-prometheus-0|data-prometheus-1|data-prometheus-2|datadir-mongodb-0|datadir-mongodb-1|datadir-mongodb-2|elasticsearch-data-elasticsearch-es-aura-0|elasticsearch-data-elasticsearch-es-aura-1|elasticsearch-data-elasticsearch-es-aura-2|grafana-grafana-0|redis-data-redis-0|redis-data-redis-1|redis-data-redis-2|store-thanos-store-gateway-0|store-thanos-store-gateway-1)"} / kubelet_volume_stats_inodes{kubernetes_io_hostname=~"^.*$",agentpool=~".*",persistentvolumeclaim=~"(data-prometheus-0|data-prometheus-1|data-prometheus-2|datadir-mongodb-0|datadir-mongodb-1|datadir-mongodb-2|elasticsearch-data-elasticsearch-es-aura-0|elasticsearch-data-elasticsearch-es-aura-1|elasticsearch-data-elasticsearch-es-aura-2|grafana-grafana-0|redis-data-redis-0|redis-data-redis-1|redis-data-redis-2|store-thanos-store-gateway-0|store-thanos-store-gateway-1)"})
Graph visual

1.9 - NLP provisioning dashboard
NLP provisioning dashboard
Information provided by NLP provisioning dashboard
Panels
Expected Killed Alive
Number of expected, killed and alive provisioning processes.
The queries used to get the panel information are:
nlp_provisioning_expected_alive_processes
nlp_provisioning_killed_processes
nlp_provisioning_alive_processes
An example of this panel is shown below:

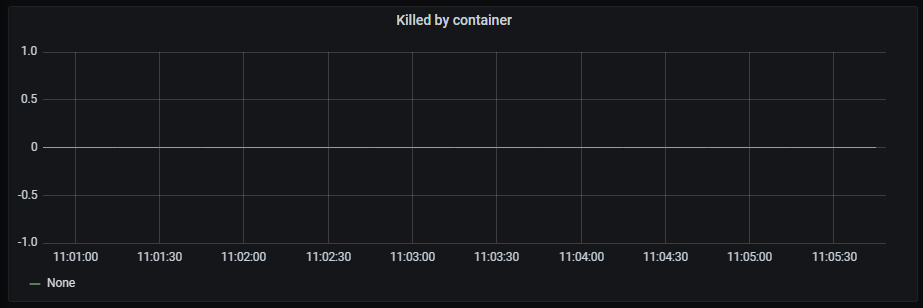
Killed by container
Time series with the killed processes by container.
The x-axis shows the time series and the y-axis shows the number of killed processes by container.
The queries used to get the panel information are:
nlp_provisioning_container_killed_count_total
An example of this panel is shown below:
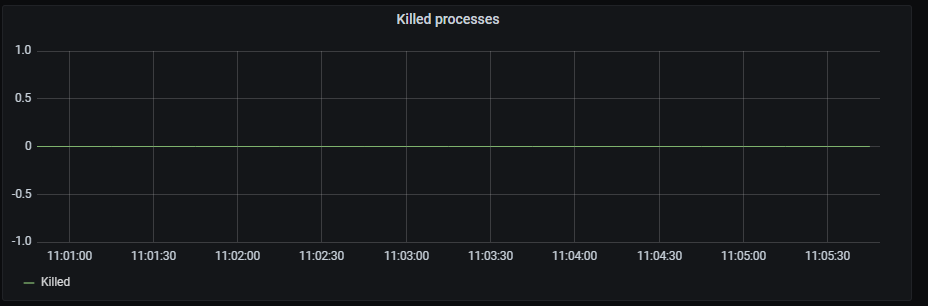
Killed processes
Time series with the total killed processes.
The x-axis shows the time series and the y-axis shows the number of killed processes.
The queries used to get the panel information are:
nlp_provisioning_killed_processes
An example of this panel is shown below:
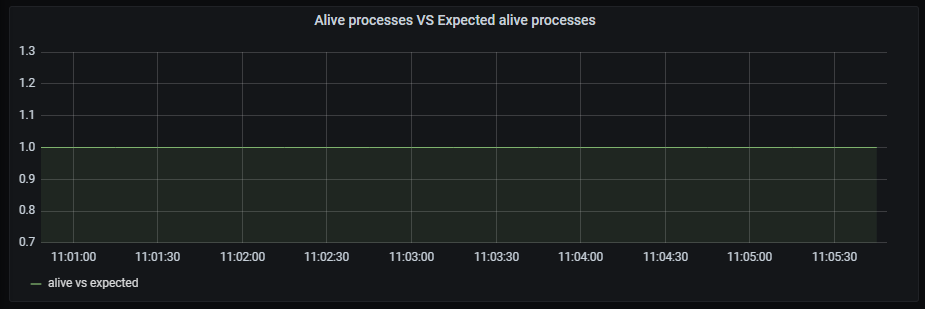
Alive processes VS Expected alive processes
Time series with the ratio between alive processes and expected alive processes.
The x-axis shows the time series and the y-axis shows the ratio between alive and expected
The queries used to get the panel information are:
nlp_provisioning_alive_processes/ nlp_provisioning_expected_alive_processes
An example of this panel is shown below:
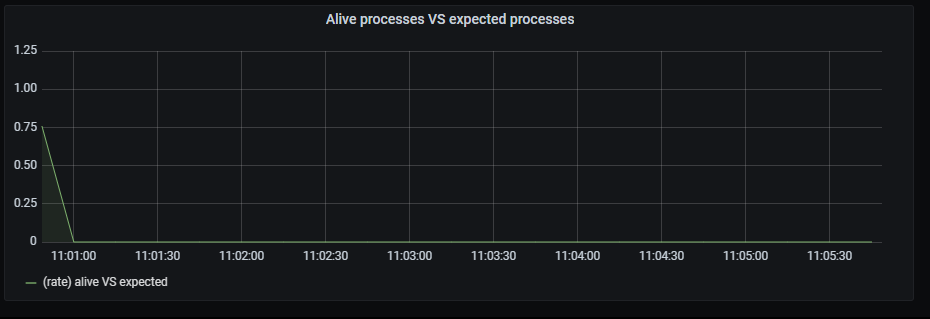
Alive processes VS expected processes
Time series with the ratio between alive processes rate aggregated by 15 minutes and expected alive processes rate aggregated by 15 minutes.
The x-axis shows the time series and the y-axis shows the ratio between alive/expected processes
The queries used to get the panel information are:
sum by (exported_job) (rate(nlp_provisioning_alive_processes{exported_job="nlp_provisioning_job"}[15m])) /
sum by (exported_job) (rate(nlp_provisioning_expected_alive_processes{exported_job="nlp_provisioning_job"}[15m]))
An example of this panel is shown below:
1.10 - Prometheus stats dashboard
Prometheus stats dashboard
Information provided by Prometheus stats dashboard
Introduction
This is a dashboard to obtain a lot of information on how Prometheus performs.
To get the information about each pod, the dashboard counts on a filter with the following fields:
jobs: list of active jobs.instances: list of scrapeable instances.interval: possible time intervals.
Once selected, the following graphs are printed.
Panels
Pods CPU usage
Time series with CPU usage rate, aggregated by one minute. It also shows the current minimum, maximum and average cpu usage.
The x-axis shows the time series and the y-axis shows the cpu usage rate.
The queries used to get the panel information are:
sum(rate(container_cpu_usage_seconds_total{pod_name!="",pod_name=~"prometheus.*"}[1m])) by (pod_name)
An example of this panel is shown below:
Pods memory usage
Time series with memory usage. It also shows the current minimum, maximum and average memory usage.
The x-axis shows the time series and the y-axis shows the memory usage.
The queries used to get the panel information are:
sum (container_memory_working_set_bytes{pod_name!="",pod_name=~"prometheus.*"}) by (pod_name)
An example of this panel is shown below:
Pods network I/O
Time series with the network I/O average aggregated by one minute. It also shows the current minimum, maximum and average network I/O bytes.
The x-axis shows the time series and the y-axis shows the network I/O.
The queries used to get the panel information are:
sum (rate (container_network_receive_bytes_total{pod_name!="",pod_name=~"prometheus.*"}[1m])) by (pod_name)
- sum (rate (container_network_transmit_bytes_total{pod_name!="",pod_name=~"prometheus.*"}[1m])) by (pod_name)
An example of this panel is shown below:

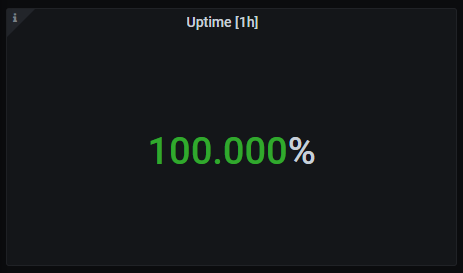
Uptime
Percentage of uptime for the last hour.
The queries used to get the panel information are:
avg(avg_over_time(up{instance=~"(10\\.240\\.0\\.10:9093|10\\.240\\.3\\.161:9093|10\\.240\\.0\\.34:9114|10\\.240\\.0\\.253:8080|10\\.240\\.3\\.205:9090|10\\.240\\.3\\.236:9090|10\\.240\\.4\\.14:9090|10\\.240\\.4\\.156:9121|10\\.240\\.4\\.186:9121|10\\.240\\.4\\.223:9121)",job=~"kubernetes-service-endpoints"}[1h]) * 100)
An example of this panel is shown below:
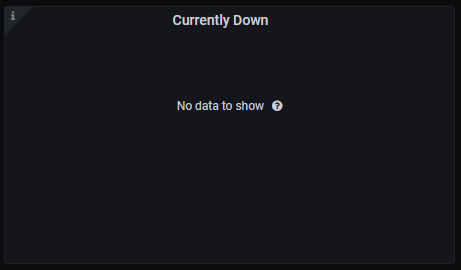
Currently down
Currently down instances.
The queries used to get the panel information are:
up{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)",job=~"kubernetes-service-endpoints"} < 1
An example of this panel is shown below:
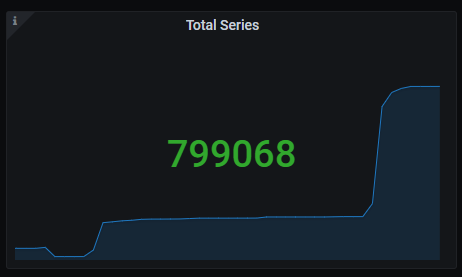
Total series
Total series count.
The queries used to get the panel information are:
sum(prometheus_tsdb_head_series{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"})
An example of this panel is shown below:
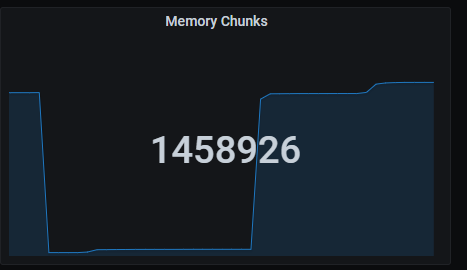
Total series
Memory chunks being used.
The queries used to get the panel information are:
sum(prometheus_tsdb_head_chunks{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"})
An example of this panel is shown below:
Quick numbers
Quick numbers section shows a series of Prometheus indicators.
Missed iterations
Number of missed iterations, aggregated by one hour.
The queries used to get the panel information are:
sum(sum_over_time(prometheus_evaluator_iterations_missed_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h]))
Skipped iterations
Number of skipped iterations, aggregated by one hour.
The queries used to get the panel information are:
sum(sum_over_time(prometheus_evaluator_iterations_skipped_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h]))
Tardy scrapes
Number of scrapes that elapsed more than expected, aggregated by one hour.
The queries used to get the panel information are:
sum(sum_over_time(prometheus_target_scrapes_exceeded_sample_limit_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h]))
Reload failures
Number of reload failures, aggregated by one hour.
The queries used to get the panel information are:
sum(sum_over_time(prometheus_tsdb_reloads_failures_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h]))
Skipped scrapes
Number of uncompleted scrapes due to multiple reasons, aggregated by one hour.
The queries used to get the panel information are:
sum(sum_over_time(prometheus_target_scrapes_exceeded_sample_limit_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h])) +
sum(sum_over_time(prometheus_target_scrapes_sample_duplicate_timestamp_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h])) +
sum(sum_over_time(prometheus_target_scrapes_sample_out_of_bounds_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h])) +
sum(sum_over_time(prometheus_target_scrapes_sample_out_of_order_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1h]))
An example of this panel is shown below:

Failures and errors
Time series with the number of several different errors and failures, aggregated by five minutes.
The x-axis shows the time series and the y-axis shows a series of different errors and failures:
- Dialer connection errors.
- Evaluator iterations missed.
- Evaluator iterations skipped.
- Evaluation failures.
- Azure refresh failures.
- Consul rpc failures.
- Dns lookup failures.
- Ec2 refresh failures.
- Gce refresh failures.
- Marathon refresh failures.
- Openstack refresh failures.
- Triton refresh failures.
- Scrapes exceeded sample limit.
- Scrapes sample duplicate timestamp.
- Scrapes sample out of bounds.
- Treecache zookeeper failures.
- Tsdb compactions failed.
- Tsdb head series not found.
- Tsdb reloads failures.
The queries used to get the panel information are:
sum(increase(net_conntrack_dialer_conn_failed_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_evaluator_iterations_missed_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_evaluator_iterations_skipped_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_rule_evaluation_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_azure_refresh_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_consul_rpc_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_dns_lookup_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_ec2_refresh_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_gce_refresh_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_marathon_refresh_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_openstack_refresh_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_sd_triton_refresh_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_target_scrapes_exceeded_sample_limit_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_target_scrapes_sample_duplicate_timestamp_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_target_scrapes_sample_out_of_bounds_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_target_scrapes_sample_out_of_order_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_treecache_zookeeper_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_tsdb_compactions_failed_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_tsdb_head_series_not_found{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
sum(increase(prometheus_tsdb_reloads_failures_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])) > 0
An example of how this panel looks like:

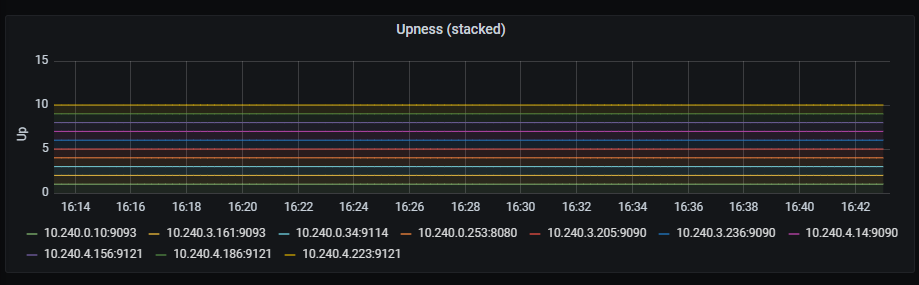
Upness (stacked)
Time series with a time bound representation of services upness. Those values are shown stacked.
The x-axis shows the time series and the y-axis shows the upness state of the different services.
The queries used to get the panel information are:
up{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)",job=~"kubernetes-service-endpoints"}
An example of this panel is shown below:
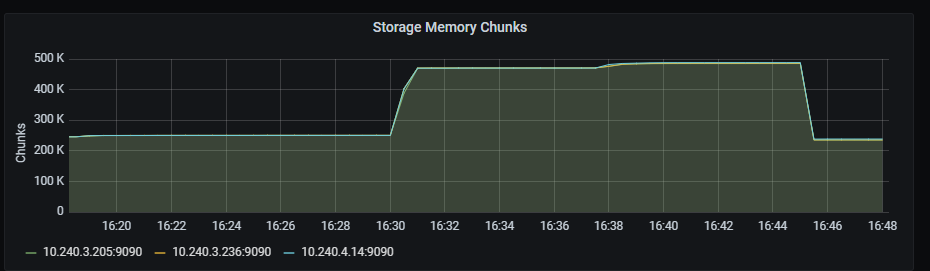
Storage memory chunks
Time series with the number of memory chunks used.
The x-axis shows the time series and the y-axis shows the number of memory chunks.
The queries used to get the panel information are:
prometheus_tsdb_head_chunks{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}
An example of this panel is shown below:
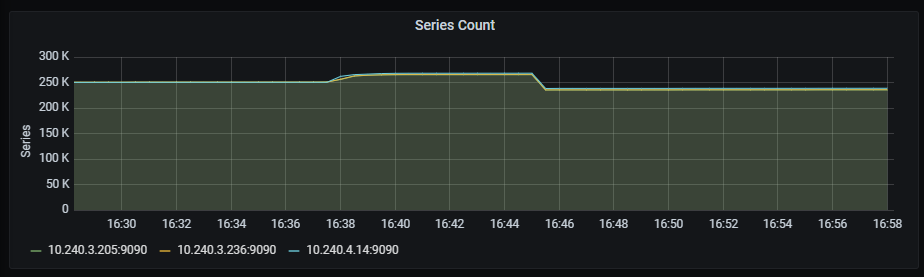
Series count
Time series with the number of tsdb series.
The x-axis shows the time series and the y-axis shows the number of series.
The queries used to get the panel information are:
prometheus_tsdb_head_series{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}
An example of this panel is shown below:
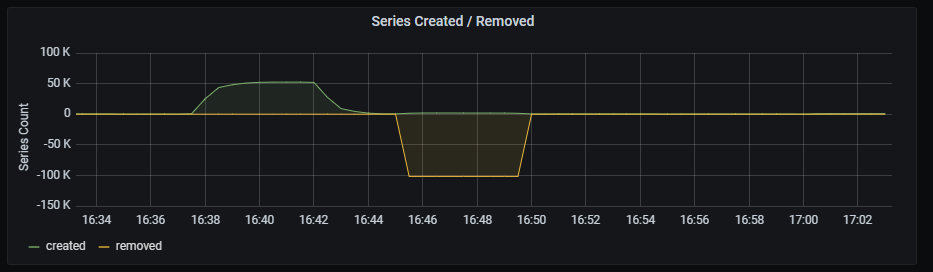
Series created/removed
Time series with the number of tsdb series created/removed.
The x-axis shows the time series and the y-axis shows the number of series created/removed, aggregated by 5 minutes.
The queries used to get the panel information are:
sum( increase(prometheus_tsdb_head_series_created_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m]) )
sum( increase(prometheus_tsdb_head_series_removed_total{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m]) )
An example of this panel is shown below:
Appended samples per second
Time series with the number of metrics per second stored by Prometheus.
The x-axis shows the time series and the y-axis shows the number of metrics per second stored by Prometheus.
The queries used to get the panel information are:
rate(prometheus_tsdb_head_samples_appended_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1m])
An example of this panel is shown below:

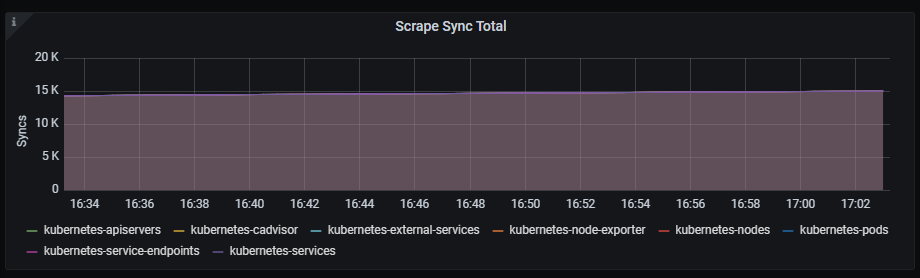
Scrape Sync total
Time series with the total number of syncs that were executed on a scrape pool.
The x-axis shows the time series and the y-axis shows the total number of syncs that were executed on a scrape pool.
The queries used to get the panel information are:
sum(prometheus_target_scrape_pool_sync_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}) by (scrape_job)
An example of this panel is shown below:
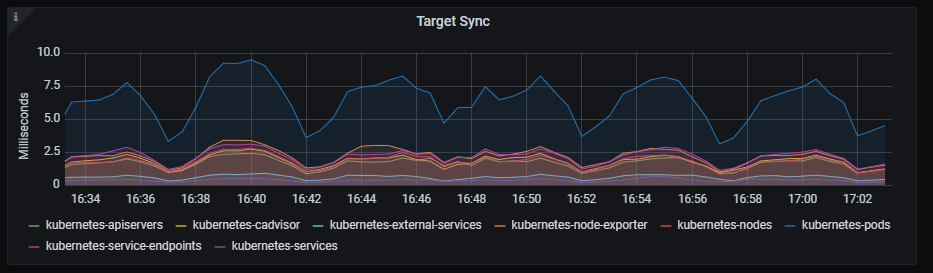
Target sync
Time series with the interval to sync the scrape pool.
The x-axis shows the time series and the y-axis shows the interval to sync the scrape pool.
The queries used to get the panel information are:
sum(rate(prometheus_target_sync_length_seconds_sum{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[2m])) by (scrape_job) * 1000
An example of this panel is shown below:
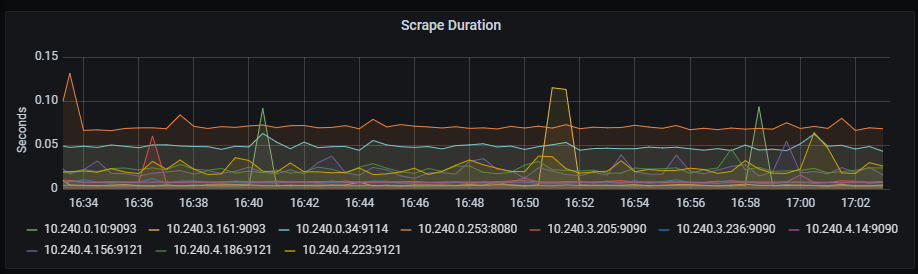
Scrape duration
Time series with the scrape duration in seconds.
The x-axis shows the time series and the y-axis shows the scrape duration in seconds.
The queries used to get the panel information are:
scrape_duration_seconds{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}
An example of this panel is shown below:
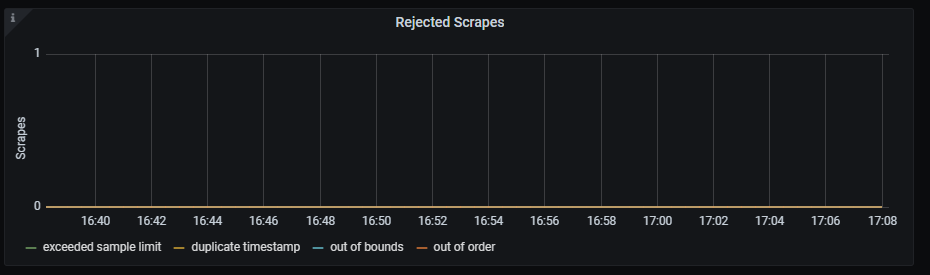
Rejected scrapes
Time series with the rejected scrapes.
The x-axis shows the time series and the y-axis shows the rejected scrapes for several reasons:
- Total number of scrapes that hit the sample limit and were rejected.
- Total number of scrapes samples duplicated.
- Total number of scrapes samples out of bounds.
- Total number of scrapes samples out of order.
The queries used to get the panel information are:
sum(prometheus_target_scrapes_exceeded_sample_limit_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"})
sum(prometheus_target_scrapes_sample_duplicate_timestamp_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"})
sum(prometheus_target_scrapes_sample_out_of_bounds_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"})
sum(prometheus_target_scrapes_sample_out_of_order_total{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"})
An example of this panel is shown below:
Average rule evaluation duration
Time series with the average duration of rule group evaluations, aggregated by five minutes.
The x-axis shows the time series and the y-axis shows the average duration of rule group evaluations.
The queries used to get the panel information are:
1000 * rate(prometheus_evaluator_duration_seconds_sum{job=~"kubernetes-service-endpoints", instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m]) /
rate(prometheus_evaluator_duration_seconds_count{job=~"kubernetes-service-endpoints", instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m])
An example of this panel is shown below:
HTTP request duration
Time series with the HTTP request duration, aggregated by one minute.
The x-axis shows the time series and the y-axis shows the http request duration.
The queries used to get the panel information are:
sum(rate(http_request_duration_microseconds_count{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[1m])) by (handler) > 0
An example of this panel is shown below:
Prometheus engine query duration seconds
Time series with the engine query duration in seconds.
The x-axis shows the time series and the y-axis shows the engine query duration.
The queries used to get the panel information are:
sum(prometheus_engine_query_duration_seconds_sum{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}) by (slice)
An example of this panel is shown below:
Rule evaluator iterations
Time series with the number of scheduled rule group evaluations, whether executed, missed or skipped.
The x-axis shows the time series and the y-axis shows the number of scheduled rule group evaluations.
The queries used to get the panel information are:
sum(rate(prometheus_evaluator_iterations_total{job=~"kubernetes-service-endpoints", instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m]))
sum(rate(prometheus_evaluator_iterations_missed_total{job=~"kubernetes-service-endpoints", instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m]))
sum(rate(prometheus_evaluator_iterations_skipped_total{job=~"kubernetes-service-endpoints", instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}[5m]))
An example of this panel is shown below:
Notifications sent
Time series with the rate of sent notifications, aggregated by 5 minutes.
The x-axis shows the time series and the y-axis shows the rate of sent notifications.
The queries used to get the panel information are:
rate(prometheus_notifications_sent_total[5m])
An example of this panel is shown below:

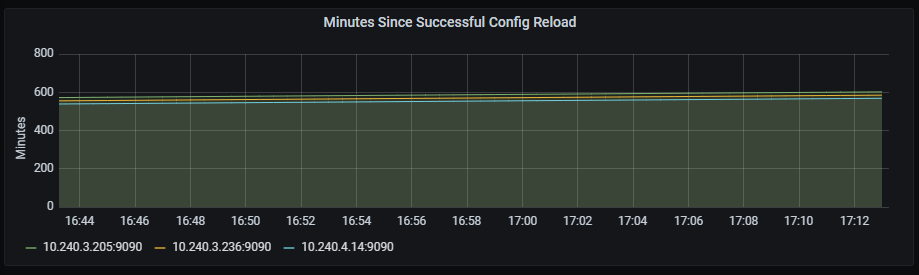
Minutes since successful config reload
Time series with the number of minutes since the last successful config reload.
The x-axis shows the time series and the y-axis shows the number of minutes since the last successful reload.
The queries used to get the panel information are:
(time() - prometheus_config_last_reload_success_timestamp_seconds{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}) / 60
An example of this panel is shown below:
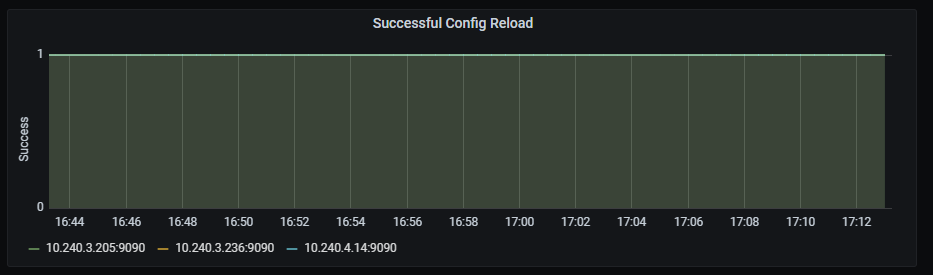
Successful config reload
Time series with the last successful reload.
The x-axis shows the time series and the y-axis shows the last successful reload.
The queries used to get the panel information are:
prometheus_config_last_reload_successful{job=~"kubernetes-service-endpoints",instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)"}
An example of this panel is shown below:
GC rate
Time series with the GC invocation durations rate, aggregated by two minutes.
The x-axis shows the time series and the y-axis shows the GC invocation durations rate.
The queries used to get the panel information are:
sum(rate(go_gc_duration_seconds_sum{instance=~"(10\\.240\\.0\\.5:9093|10\\.240\\.0\\.76:9093|10\\.240\\.0\\.26:9114|10\\.240\\.0\\.253:8080|10\\.240\\.0\\.94:9090|10\\.240\\.1\\.199:9090|10\\.240\\.2\\.4:9090|10\\.240\\.2\\.204:9121|10\\.240\\.2\\.245:9121|10\\.240\\.3\\.10:9121)",job=~"kubernetes-service-endpoints"}[2m])) by (instance)
An example of this panel is shown below:

1.11 - Redis dashboard
Redis dashboard
Information provided by Redis dashboard
Introduction
Redis dashboard monitors multiple data and service-related metrics.
The available metrics are defined in the following sections.
Redis uptime
Uptime graph shows time since last restart/shutdown.
Metrics:
max(max_over_time(redis_uptime_in_seconds{kubernetes_name=~"redis-announce-0"}[$__interval]))
Graph visual
Redis clients
Clients graph shows number of connected clients.
Metrics:
redis_connected_clients{kubernetes_name=~"redis-announce-0"}
Graph visual
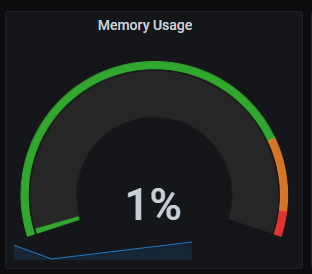
Redis memory usage
Memory usage graph shows percentage of used memory.
Metrics:
100 * (redis_memory_used_bytes{kubernetes_name=~"redis-announce-0"} / redis_memory_max_bytes{kubernetes_name=~"redis-announce-0"} )
Graph visual
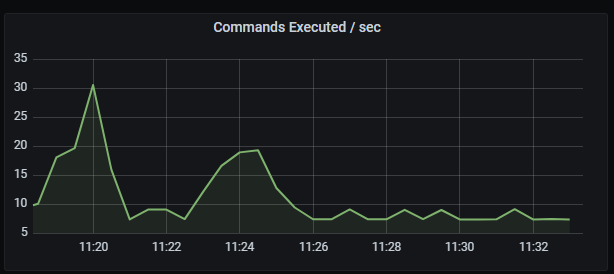
Redis commands executed per second
Commands executed per second graph shows the rate of commands executed per second, aggregated by one minute.
Metrics:
rate(redis_commands_processed_total{kubernetes_name=~"redis-announce-0"}[1m])
Graph visual
Redis commands executed per second
Commands executed per second graph shows the rate of commands executed per second, aggregated by one minute.
Metrics:
rate(redis_commands_processed_total{kubernetes_name=~"redis-announce-0"}[1m])
Graph visual
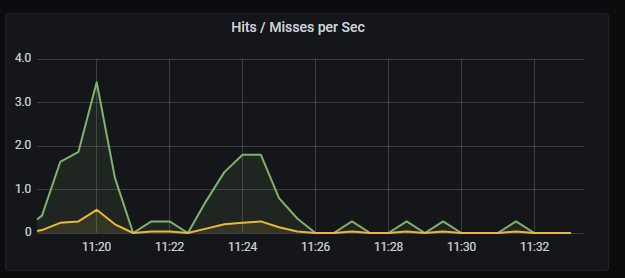
Redis hits/missed per second
Hits/missed per second graph shows the rate of hits and misses per second, aggregated by five minutes.
Metrics:
It includes two metrics:
irate(redis_keyspace_hits_total{kubernetes_name=~"redis-announce-0"}[5m])
irate(redis_keyspace_hits_total{kubernetes_name=~"redis-announce-0"}[5m])
Graph visual
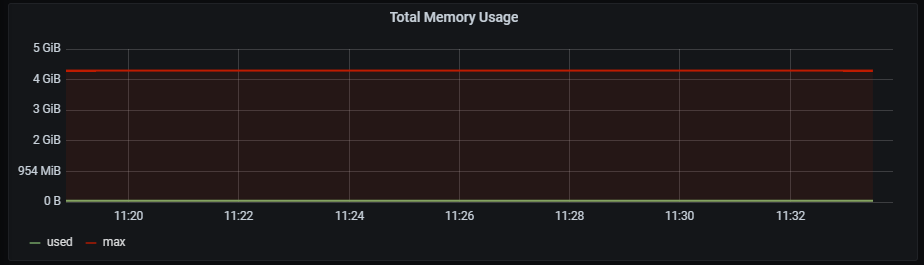
Redis total memory usage
Total memory usage graph shows total memory usage and total memory free + used.
Metrics:
It includes two metrics:
redis_memory_used_bytes{kubernetes_name=~"redis-announce-0"}
redis_memory_max_bytes{kubernetes_name=~"redis-announce-0"}
Graph visual
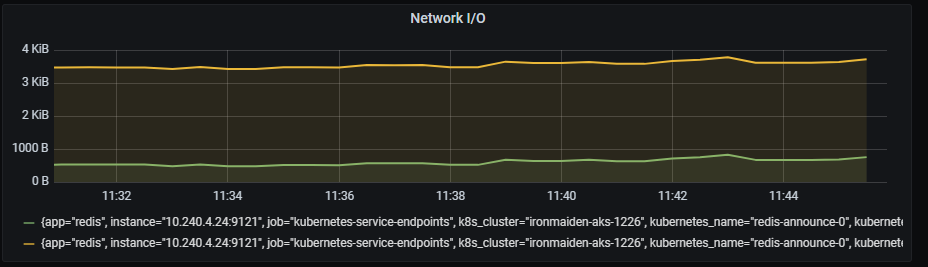
Redis network I/O
Network I/O graph shows rate of total in/out bytes, aggregated by 5 minutes.
Metrics:
It includes two metrics:
rate(redis_net_input_bytes_total{kubernetes_name=~"redis-announce-0"}[5m])
rate(redis_net_output_bytes_total{kubernetes_name=~"redis-announce-0"}[5m])
Graph visual
Redis total items per DB
Total items per DB graph shows total number of items separated by db number.
Metrics:
sum (redis_db_keys{kubernetes_name=~"redis-announce-0"}) by (db) > 0
Graph visual
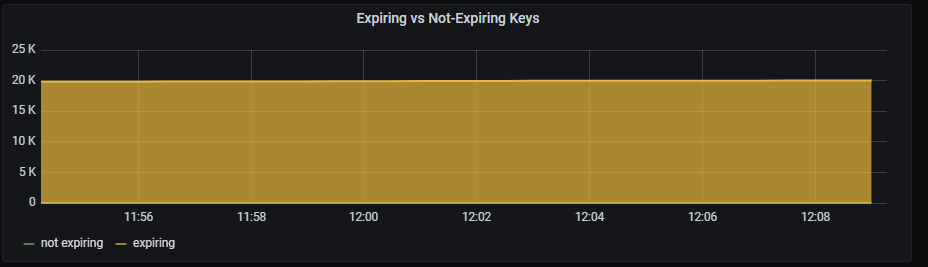
Redis expiring vs not-expiring keys
Expiring vs not-expiring keys graph shows total number of expiring and not expiring keys.
Metrics:
It includes two metrics:
sum (redis_db_keys{kubernetes_name=~"redis-announce-0"}) - sum (redis_db_keys_expiring{kubernetes_name=~"redis-announce-0"})
sum (redis_db_keys_expiring{kubernetes_name=~"redis-announce-0"})
Graph visual
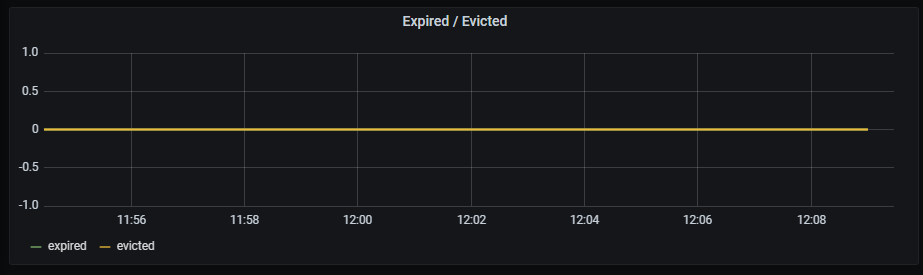
Redis expired/evicted
Expired/evicted graph shows total number of expired and evicted keys, aggregated by 5 minutes.
Metrics:
It includes two metrics:
sum(rate(redis_expired_keys_total{kubernetes_name=~"redis-announce-0"}[5m])) by (kubernetes_name)
sum(rate(redis_evicted_keys_total{kubernetes_name=~"redis-announce-0"}[5m])) by (kubernetes_name)
Graph visual
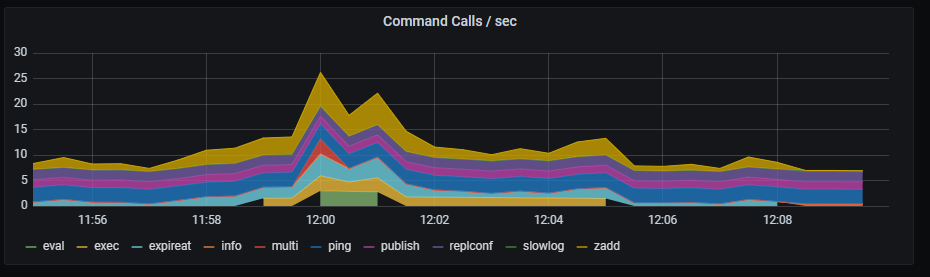
Redis command calls per second
Command calls per second graph shows top commands number of executions rate, aggregated by 5 minutes.
Metrics:
topk(5, irate(redis_commands_total{kubernetes_name=~"redis-announce-0"} [1m]))
Graph visual
2 - Aura components dashboards
Aura components dashboards
Grafana dashboards with metrics related to the performance of specific Aura components
Introduction
Currently, these are the available dashboards for Aura components in Grafana based on metrics stored in Prometheus:
2.1 - Aura bot latencies dashboard
Aura bot latencies dashboard
Information provided by Aura bot latencies dashboard
Introduction
Aura bot latencies dashboard monitors outbound and inbound latencies on the request and responses handled directly by aura-bot.
The available metrics are defined in the following sections, corresponding to request errors and latency for requests, Microsoft APIs, Kernel APIs, Cognitive APIs, aura-services APIs and other APIs.
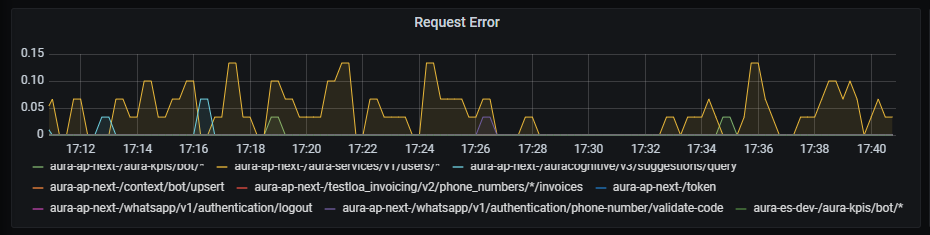
Request error
Request error graph shows the number of errors rate, aggregated by one minute.
Graph metrics
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",status=~"4..|500"}[1m]))
Graph visual
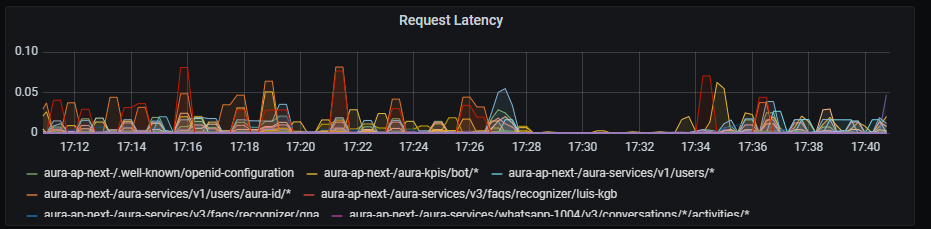
Request latency
Request latency graph shows latency rate for outgoing traffic, aggregated by one minute.
Graph metrics
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_sum{app="aura-bot"}[1m]))
Graph visual
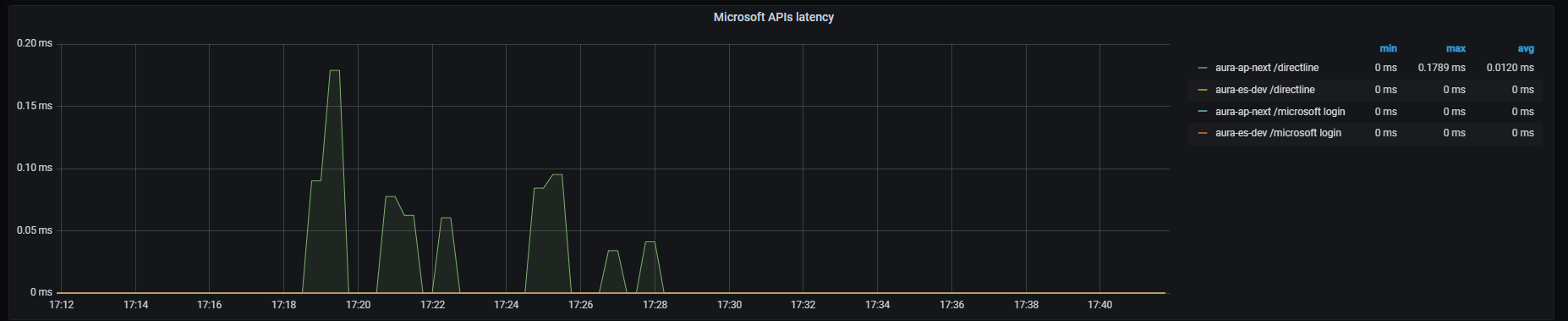
Microsoft APIs latency
Microsoft APIs latency graph shows mean latency rate for the different Microsoft APIs used.
Graph metrics
Currently, there are three monitored Microsoft endpoints:
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"directline.botframework.com"}[1m]))/
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"directline.botframework.com"}[1m]))
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"login.microsoftonline.com"}[1m]))/
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"login.microsoftonline.com"}[1m]))
sum (label_replace(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"aura.*blob.core.windows.net",path=~"/aura-temporary-resources/.*"},"path_set","$1","path","/aura-temporary-resources/.*")) by (path_set,kubernetes_namespace) /
sum (label_replace(outgoing_request_duration_seconds_count{app="aura-bot",host=~"aura.*blob.core.windows.net",path=~"/aura-temporary-resources/.*"},"path_set","$1","path","/aura-temporary-resources/.*")) by (path_set,kubernetes_namespace)
Graph visual
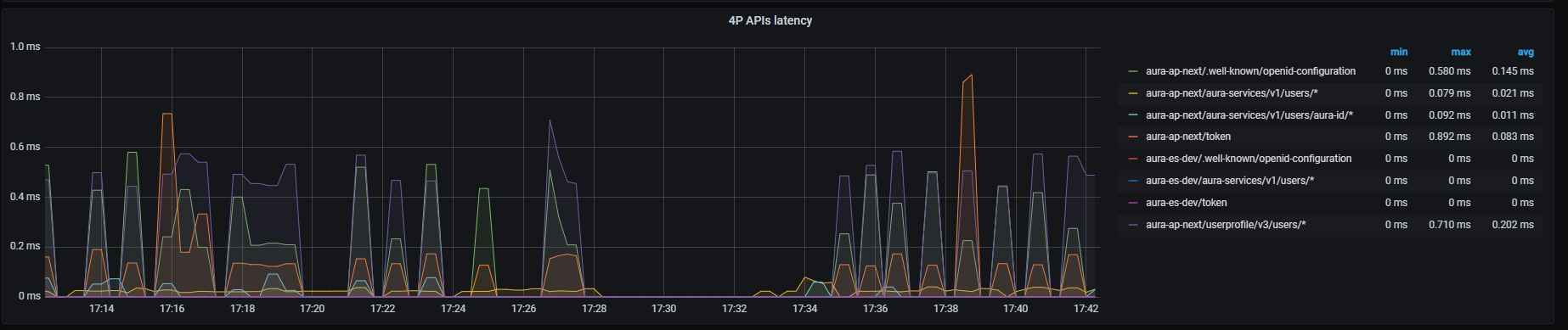
Kernel APIs latency
Kernel APIs latency graph shows mean latency rate for the different Kernel APIs used.
Graph metrics
Currently, there are four monitored Kernel endpoints (more can be added if necessary for a given environment):
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"auth.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"auth.*"}[1m]))
- Kernel subscribed products endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"api.*",path=~"/subscribed_products/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"api.*",path=~"/subscribed_products/.*"}[1m]))
- Kernel user profile endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"api.*",path=~"/userprofile/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"api.*",path=~"/userprofile/.*"}[1m]))
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"api.*",path=~"/invoicing/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"api.*",path=~"/invoicing/.*"}[1m]))
Graph visual
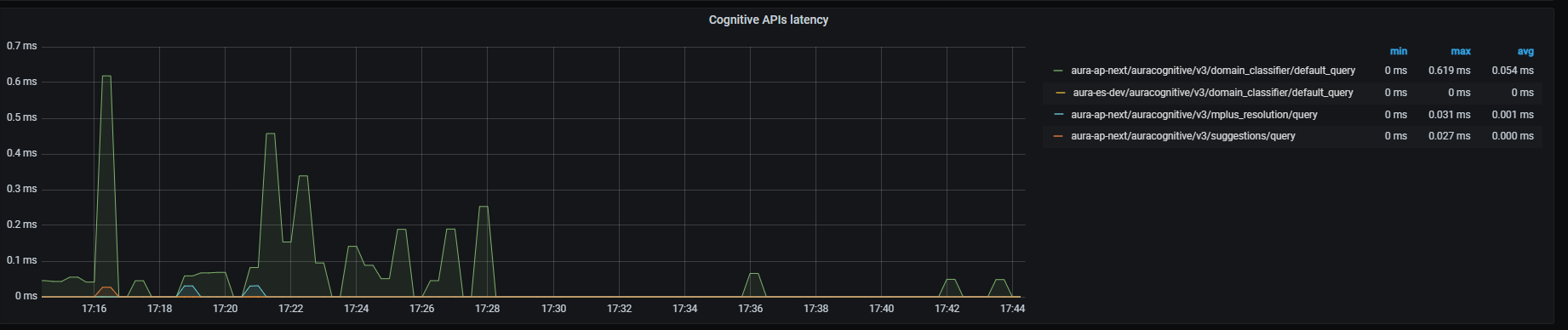
Cognitive APIs latency
Cognitive APIs latency graph shows mean latency rate for the different cognitive APIs used.
Graph metrics
Currently, there are three monitored Cognitive endpoints:
- Domain classifier endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"api-.*",path=~"/auracognitive/v3/domain_classifier/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"api-.*",path=~"/auracognitive/v3/domain_classifier/.*"}[1m]))
- Mplus resolution endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"api-.*",path=~"/auracognitive/v3/mplus_resolution/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"api-.*",path=~"/auracognitive/v3/mplus_resolution/.*"}[1m]))
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="aura-bot",host=~"api-.*",path=~"/auracognitive/v3/suggestions/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="aura-bot",host=~"api-.*",path=~"/auracognitive/v3/suggestions/.*"}[1m]))
Graph visual
Aura-services APIs latency
Graph metrics
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_sum{app="aura-bot", path=~"/aura-services/.*"}[1m]))/
sum by (path,kubernetes_namespace)(rate(outgoing_request_duration_seconds_count{app="aura-bot", path=~"/aura-services/.*"}[1m]))
Graph visual
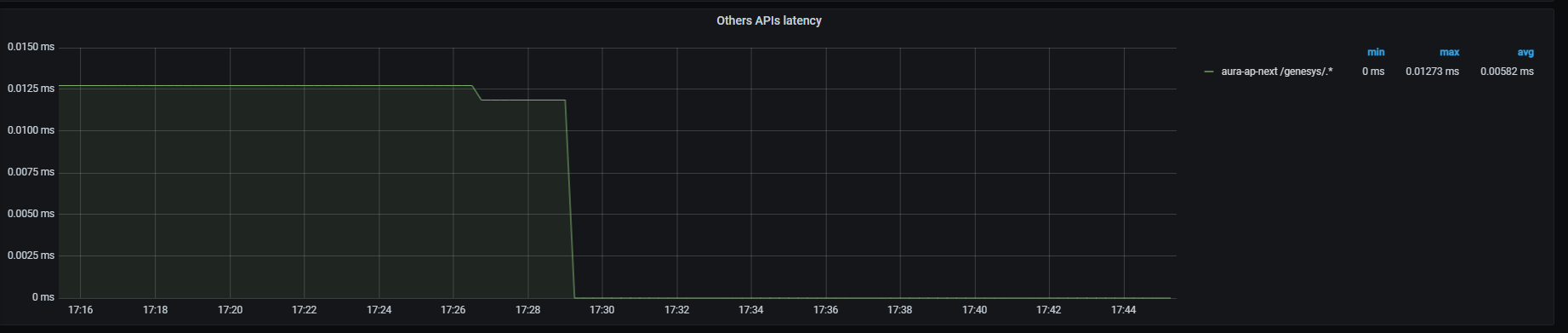
Other APIs latency
Other APIs latency graph shows mean latency rate for traffic directed to other APIs different from those above, aggregated by one minute.
Graph metrics
Currently, the only API monitored is Genesys API:
sum (label_replace(outgoing_request_duration_seconds_sum{app="aura-bot",path=~"/genesys/.*"},"path_set","$1","path","/genesys/.*")) by (path_set,kubernetes_namespace) / sum (label_replace(outgoing_request_duration_seconds_count{app="aura-bot",path=~"/genesys/.*"},"path_set","$1","path","/genesys/.*")) by (path_set,kubernetes_namespace)
Graph visual
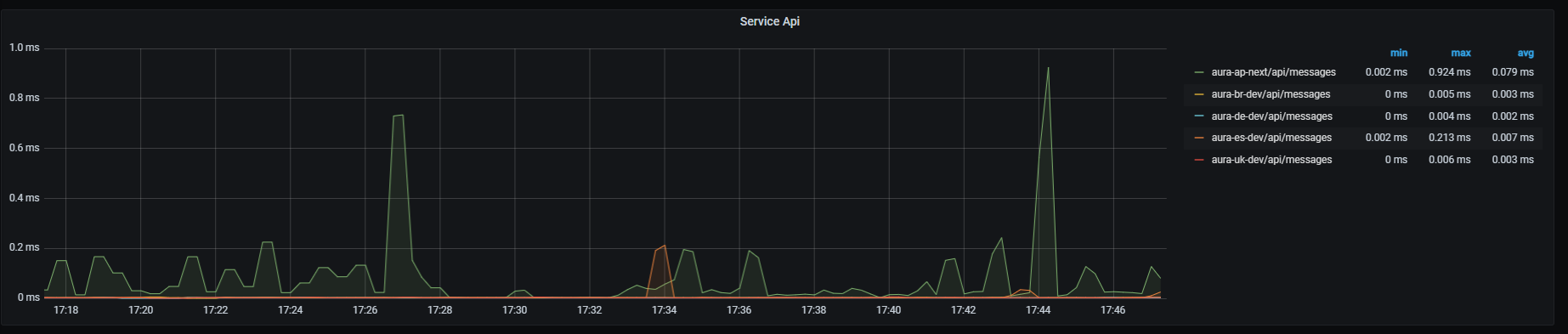
Service API
Service API graph shows mean latency rate for the main endpoint on aura-bridge, that receives requests from Direct Line and aura-bridge. Aggregated by one minute.
Graph metrics
sum by (path,kubernetes_namespace)(rate(http_request_duration_seconds_sum{path=~"/api/messages"}[1m]))/
sum by (path,kubernetes_namespace)(rate(http_request_duration_seconds_count{path=~"/api/messages"}[1m]))
Graph visual
2.2 - Aura bridge dashboard
Aura bridge dashboard
Information provided by Aura bridge dashboard
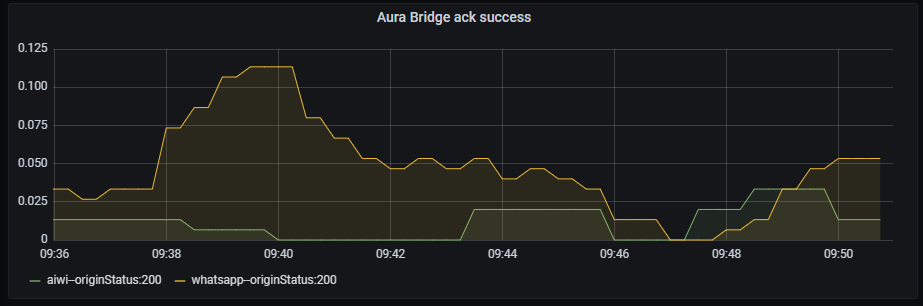
Aura bridge ack success
Ack success graph shows the number of successful acks rate, aggregated by three minutes.
The available metrics are defined in the following sections.
Graph metrics
sum by (origin,originStatus)(rate(aura_response_ack_duration_seconds_count{app="aura-bridge",origin=~"aura-bot|whatsapp|4p",originStatus="200"}[3m]))
Graph visual
Aura bridge ack error
Ack error graph shows acks rate with an error status, aggregated by three minutes.
Graph metrics
sum by (origin,originStatus)(rate(aura_response_ack_duration_seconds_count{app="aura-bridge",origin=~"aura-bot|whatsapp|4p",originStatus!="200"}[3m]))
Graph visual
Aura bridge message success
Message success graph shows the number of successful messages rate, aggregated by three minutes.
Graph metrics
sum by (origin,originStatus)(rate(outgoing_message_duration_seconds_count{app="aura-bridge",origin=~"aura-bot|whatsapp|4p",originStatus="200"}[3m]))
Graph visual

Aura bridge message error
Message error graph shows number of erroneous messages rate, aggregated by three minutes.
Graph metrics
sum by (origin,originStatus)(rate(outgoing_message_duration_seconds_count{app="aura-bridge",origin=~"aura-bot|whatsapp|4p",originStatus!="200"}[3m]))
Graph visual

Aura bridge bot message error
They correspond to errors that aura-bridge receives from aura-bot. Bot message error graph shows the number of erroneous messages (sent by aura-bot) rate, aggregated by three minutes.
Graph metrics
sum by (origin,originStatus)(rate(outgoing_message_duration_seconds_count{app="aura-bridge",origin=~"aura-bot",originStatus!="200"}[3m]))
Graph visual
Aura bridge message - Kernel internal error
Kernel internal error graph shows number of erroneous messages (sent by Kernel) rate, regardless of the error type and aggregated by three minutes.
Graph metrics
sum by (origin,originStatus)(rate(outgoing_message_duration_seconds_count{app="aura-bridge",origin=~"4p",originStatus!="200"}[3m]))
Graph visual
Aura bridge message - Kernel HTTP error
Kernel HTTP error graph shows number of erroneous messages (sent by Kernel) rate, filtered by HTTP client errors and aggregated by three minutes.
Graph metrics
sum by (origin,httpStatus)(rate(outgoing_message_duration_seconds_count{app="aura-bridge",origin=~"4p",httpStatus=~"4.."}[3m]))
Graph visual
2.3 - Authentication API dashboard
Aura authentication API dashboard
Information provided by Authentication API dashboard
Aura services latency
Aura services latency graph shows mean latency rate for the different incoming calls.
The available metrics are defined in the following sections.
Graph metrics
Currently, these are the existing monitored incoming calls:
- WhatsApp users’ retrieval
sum by (kubernetes_namespace,path)(rate(http_request_duration_seconds_sum{path=~"/aura-services/v1/users/whatsapp.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(http_request_duration_seconds_count{path=~"/aura-services/v1/users/whatsapp.*"}[1m]))
sum by (kubernetes_namespace,path)(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/users/aura-id"})/
sum by (kubernetes_namespace,path)(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/users/aura-id"})
sum (label_replace(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/users/aura-id/.*"},"path_set","$1","path","/aura-services/v1/users/aura-id/.*")) by (kubernetes_namespace,path_set) /
sum (label_replace(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/users/aura-id/.*"},"path_set","$1","path","/aura-services/v1/users/aura-id/.*")) by (kubernetes_namespace,path_set)
- Retrieves an Aura user by the given
auraIdGlobal and the channelId
sum (label_replace(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/users/aura-id-global/.*"},"path_set","$1","path","/aura-services/v1/users/aura-id-global/.*")) by (kubernetes_namespace,path_set) /
sum (label_replace(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/users/aura-id-global/.*"},"path_set","$1","path","/aura-services/v1/users/aura-id-global/.*")) by (kubernetes_namespace,path_set)
- Gets given authorization and identification information to register the user
sum (label_replace(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/users/auraid/integrated/.*"},"path_set","$1","path","/aura-services/v1/users/auraid/integrated/.*")) by (kubernetes_namespace,path_set) /
sum (label_replace(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/users/auraid/integrated/.*"},"path_set","$1","path","/aura-services/v1/users/auraid/integrated/.*")) by (kubernetes_namespace,path_set)
sum by (kubernetes_namespace,path)(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/users/auraid/integrated/logout"})/
sum by (kubernetes_namespace,path)(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/users/auraid/integrated/logout"})
sum by (kubernetes_namespace,path)(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/token"})/
sum by (kubernetes_namespace,path)(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/token"})
- New Direct Line token(wss)
sum by (kubernetes_namespace,path)(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/token/wss"})/
sum by (kubernetes_namespace,path)(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/token/wss"})
sum by (kubernetes_namespace,path)(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/openid/issuer/.well-known/openid-configuration"})/
sum by (kubernetes_namespace,path)(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/openid/issuer/.well-known/openid-configuration"})
sum by (kubernetes_namespace,path)(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/openid/jwk"})/
sum by (kubernetes_namespace,path)(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/openid/jwk"})
sum (label_replace(http_request_duration_seconds_sum{app="authentication-api",path=~"/users/aura-id/.*"},"path_set","$1","path","/users/aura-id/.*")) by (kubernetes_namespace,path_set) /
sum (label_replace(http_request_duration_seconds_count{app="authentication-api",path=~"/users/aura-id/.*"},"path_set","$1","path","/users/aura-id/.*")) by (kubernetes_namespace,path_set)
sum (label_replace(http_request_duration_seconds_sum{app="authentication-api",path=~"/aura-services/v1/admin/users/phone-numbers/.*"},"path_set","$1","path","/aura-services/v1/admin/users/phone-numbers/.*")) by (kubernetes_namespace,path_set) /
sum (label_replace(http_request_duration_seconds_count{app="authentication-api",path=~"/aura-services/v1/admin/users/phone-numbers/.*"},"path_set","$1","path","/aura-services/v1/admin/users/phone-numbers/.*")) by (kubernetes_namespace,path_set)
Graph visual
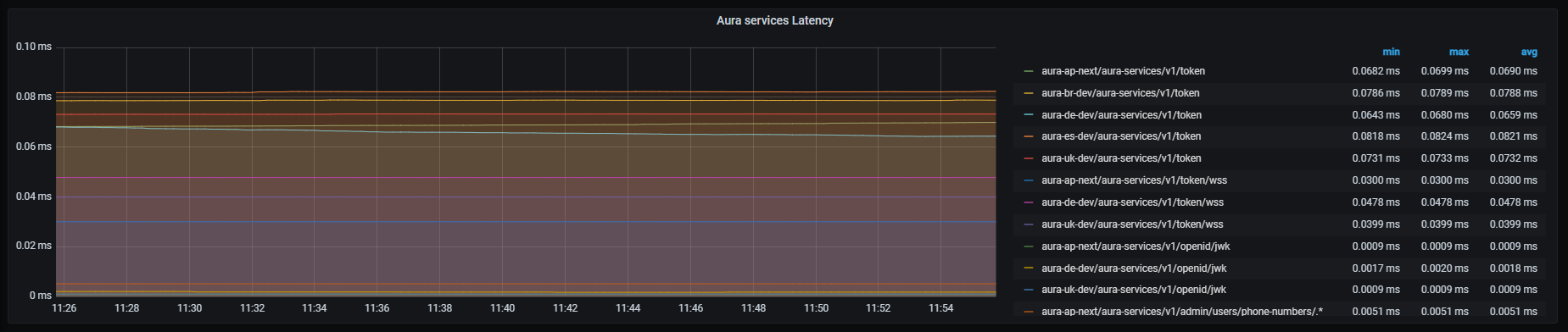
Request out error
Request out error graph shows error rate for outgoing requests with HTTP codes 4xx and 5xx, aggregated by 1 minute.
Graph metrics
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",status=~"4..|5.."}[1m]))
Graph visual

Microsoft APIs latency
Microsoft APIs latency graph shows mean latency rate for the different Microsoft APIs used.
Graph metrics
Currently, there are three monitored Microsoft endpoints:
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="authentication-api",host=~"directline.botframework.com"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",host=~"directline.botframework.com"}[1m]))
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="authentication-api",host=~"login.microsoftonline.com"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",host=~"login.microsoftonline.com"}[1m]))
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="authentication-api",host=~"aura.*.blob.core.windows.net"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",host=~"aura.*.blob.core.windows.net"}[1m]))
Graph visual

Kernel APIs latency
Kernel APIs latency graph shows mean latency rate for the different Kernel APIs used.
Graph metrics
Currently, there are three monitored Kernel endpoints:
- Kernel token retrieval endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="authentication-api",host=~"auth.*",path="/token"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",host=~"auth.*",path="/token"}[1m]))
- Kernel token introspection endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="authentication-api",host=~"api.*",path=~"/token-introspection/.*"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",host=~"api.*",path=~"/token-introspection/.*"}[1m]))
- Kernel open-id configuration endpoint
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_sum{app="authentication-api",host=~"auth.*",path="/.well-known/openid-configuration"}[1m]))/
sum by (kubernetes_namespace,path)(rate(outgoing_request_duration_seconds_count{app="authentication-api",host=~"auth.*",path="/.well-known/openid-configuration"}[1m]))
Graph visual
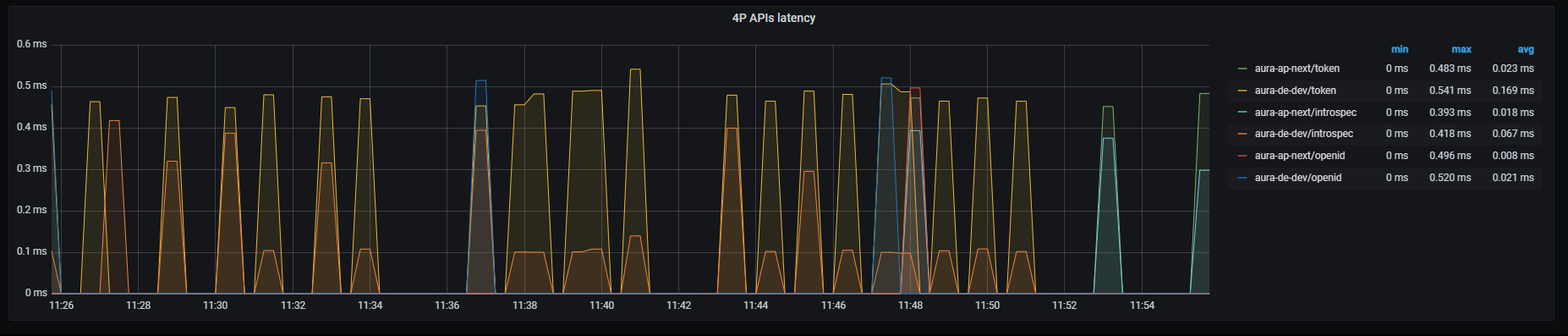
2.4 - Aura HTTP Inbound dashboard
Aura HTTP Inbound dashboard
Information provided Aura HTTP inbound dashboard
Introduction
HTTP inbound dashboard monitors inbound traffic to different services.
This inbound traffic can be visualized by channel, thus providing a detailed insight into the specific incoming traffic to this particular channel. It clearly improves the optimization of strategies for that channel or a performance comparison between different channels.
The available metrics are defined in the following sections.
HTTP request latency
HTTP request latency graph shows mean latency time aggregated by one minute.
Graph metrics
sum by (app, kubernetes_namespace)(rate(http_request_duration_seconds_sum{app=~'(aura-bot|aura-bridge|authentication-api|complex-logic|context|nlp|tac|thanos-querier)'}[1m])) /
sum by (app, kubernetes_namespace)(rate(http_request_duration_seconds_count{app=~'(aura-bot|aura-bridge|authentication-api|complex-logic|context|nlp|tac|thanos-querier)'}[1m]))
Graph visual

HTTP Request Rate
HTTP requests rate graph shows number of requests aggregated by one minute.
Graph metrics
sum by (app, kubernetes_namespace) (rate(http_request_duration_seconds_count{app=~'(aura-bot|aura-bridge|authentication-api|complex-logic|context|nlp|tac|thanos-querier)'}[1m]))
Graph visual
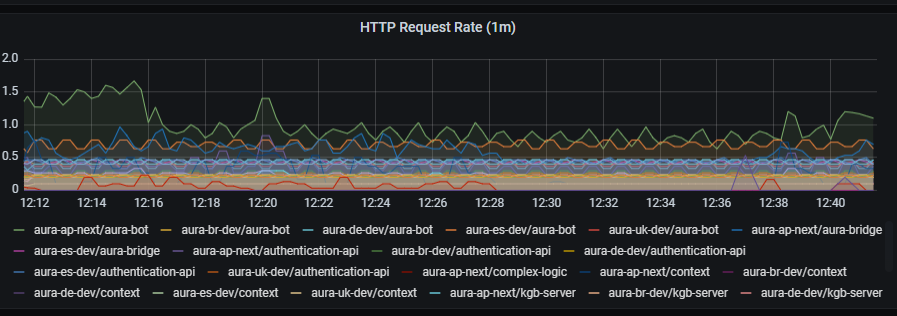
HTTP request latency
HTTP request latency graph shows request latency aggregated by one minute.
Graph metrics
sum by (app, kubernetes_namespace) (rate(http_request_duration_seconds_sum{app=~'(aura-bot|aura-bridge|authentication-api|complex-logic|context|nlp|tac|thanos-querier)'}[1m]))
Graph visual
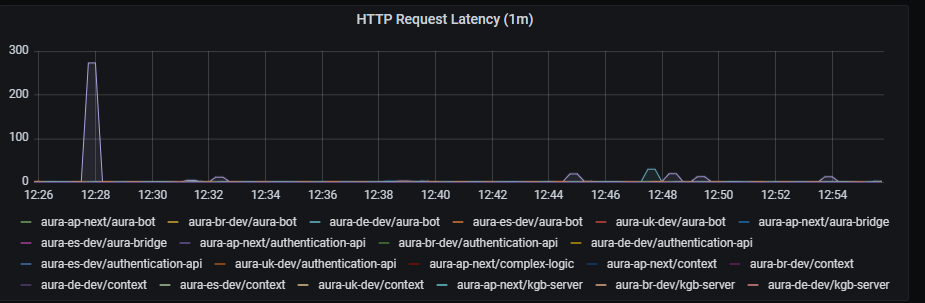
HTTP error rate
HTTP error rate shows rate of petition errors aggregated by one minute.
Graph metrics
sum by (app, kubernetes_namespace) (rate(http_request_duration_seconds_count{app=~'(aura-bot|aura-bridge|authentication-api|complex-logic|context|nlp|tac|thanos-querier)',status_code=~"4..|5.."}[1m]))
Graph visual
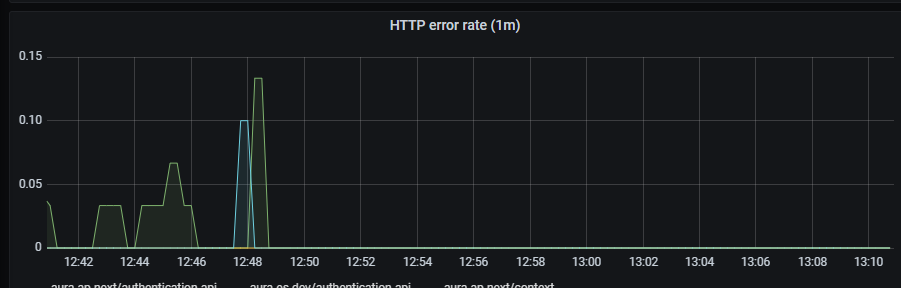
Errors
Errors graph shows errors duration aggregated by one minute.
Graph metrics
sum(rate(http_request_duration_seconds_count{app=~'(aura-bot|aura-bridge|authentication-api|complex-logic|context|nlp|tac|thanos-querier)',status_code=~"4..|5.."}[1m])) by (app, kubernetes_namespace)
Graph visual
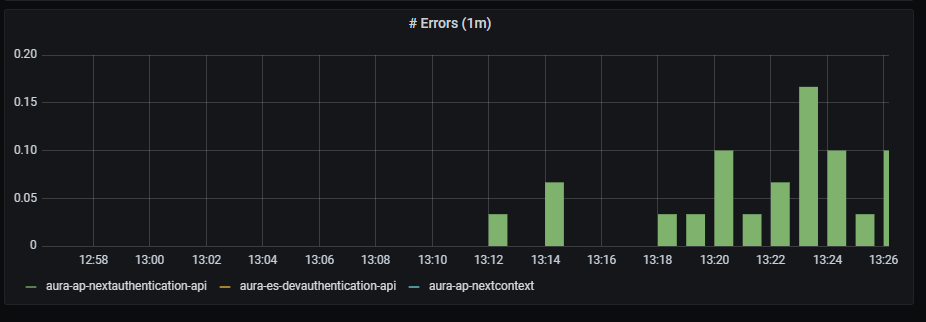
2.5 - Aura HTTP Outbound dashboard
Aura HTTP Outbound dashboard
Information provided Aura HTTP outbound dashboard
Introduction
HTTP outbound dashboard monitors outbound traffic to different services.
This outbound traffic can be visualized by channel, thus providing a detailed insight into the specific outgoing traffic from this particular channel. It clearly improves the optimization of strategies for that channel or a performance comparison between different channels.
The available metrics are defined in the following sections.
HTTP request latency
HTTP request latency graph shows mean latency time aggregated by one minute.
Graph metrics
sum by (app,kubernetes_namespace)(rate(outgoing_request_duration_seconds_sum{app=~'.*'}[1m])) / sum by (app,kubernetes_namespace)(rate(outgoing_request_duration_seconds_count{app=~'.*'}[1m]))
Graph visual

HTTP request rate
HTTP requests rate graph shows requests rate per second, aggregated by one minute.
Graph metrics
sum by (app,kubernetes_namespace) (rate(outgoing_request_duration_seconds_count{app=~'.*'}[1m]))
Graph visual
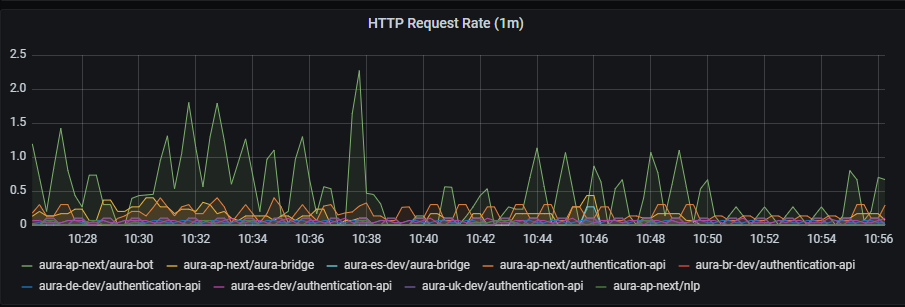
HTTP request latency
HTTP request latency graph shows request latency rate per second, aggregated by one minute.
Graph metrics
sum by (app,kubernetes_namespace) (rate(outgoing_request_duration_seconds_sum{app=~'.*'}[1m]))
Graph visual
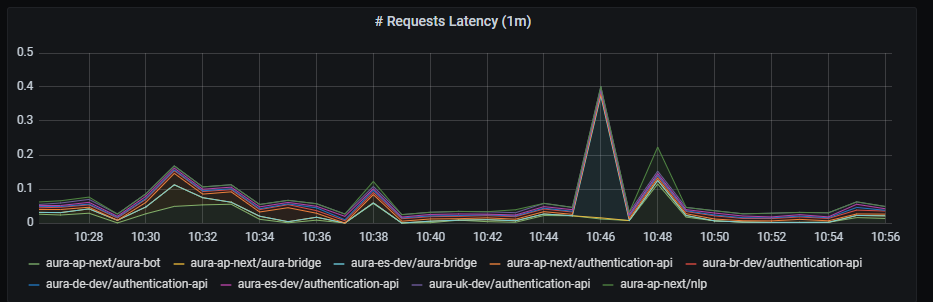
HTTP error rate
HTTP error rate shows request errors rate per second, aggregated by one minute
Graph metrics
sum by (app,kubernetes_namespace) (rate(outgoing_request_duration_seconds_count{app=~'.*',status=~"4..|5.."}[1m]))
Graph visual
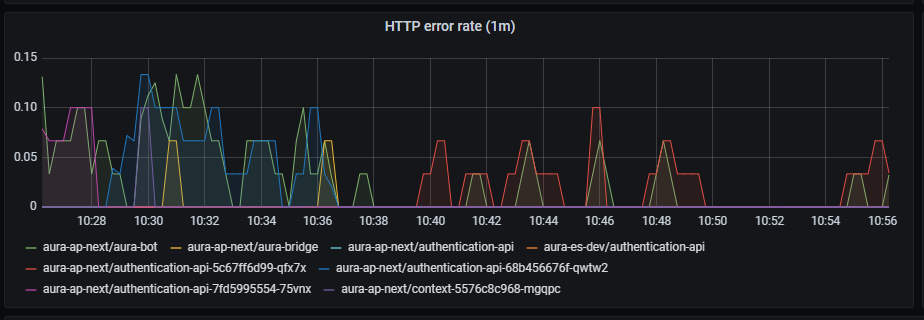
Errors
Errors graph shows errors duration aggregated by one minute.
Graph metrics
sum(rate(outgoing_request_duration_seconds_count{app=~'.*',status=~"4..|5.."}[1m])) by (app,kubernetes_namespace)
Graph visual
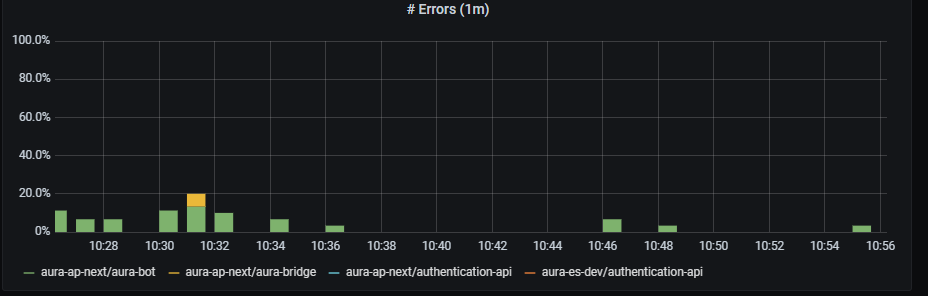
Aura bot backend latency
aura-bot backend latency shows mean latency rate on aura-bot backend, aggregated by one minute.
Graph metrics
sum(rate(outgoing_request_duration_seconds_sum{app=~"aura-bot"}[1m])) by (path,kubernetes_namespace)/sum(rate(outgoing_request_duration_seconds_count{app=~"aura-bot"}[1m])) by (path,kubernetes_namespace)
Graph visual

Authentication API backend latency
aura-authentication-api backend latency shows mean latency rate on aura-authentication-api backend, aggregated by one minute.
Graph metrics
sum(rate(outgoing_request_duration_seconds_sum{app=~"authentication-api"}[1m])) by (path,kubernetes_namespace)/sum(rate(outgoing_request_duration_seconds_count{app=~"authentication-api"}[1m])) by (path,kubernetes_namespace)
Graph visual

Aura bridge backend latency
aura-bridge backend latency shows mean latency rate on aura-bridge backend, aggregated by one minute.
Graph metrics
sum(rate(outgoing_request_duration_seconds_sum{app=~"aura-bridge"}[1m])) by (path,kubernetes_namespace)/sum(rate(outgoing_request_duration_seconds_count{app=~"aura-bridge"}[1m])) by (path,kubernetes_namespace)
Graph visual
2.6 - Pod resources dashboard
Pod resources dashboard
Information provided by Pod resources dashboard
Introduction
This is a unique dashboard to obtain the most basic information about how the environment pods behavior is.
To get the information about each pod, the dashboard counts on a filter with the following fields:
namespace: list of all the available namespaces of your deployment.pod: list of pods running in the selected namespace.container: list of containers running in the selected pod.DS_PROMETHEUS: Prometheus data source to be used. By default, Prometheus.
Once selected, the following graphs are printed, with the data of the pod.
Panels
Pod memory
Pod memory panel shows a time series with the current memory consumption in the selected pod. It also shows the current, maximum, minimum and average memory consumption of the Pod.
The x-axis shows the time series and the y-axis shows the amount of memory consumed by the pod.
The queries used to get the panel information are:
sum(kube_pod_container_resource_requests_memory_bytes{namespace="aura-<env>",pod="aura-bot-<id>"})
sum(kube_pod_container_resource_limits_memory_bytes{namespace="aura-<env>",pod="aura-bot-<id>"})
sum(container_memory_working_set_bytes{namespace="aura-<dev>",container!="POD",container!="",pod!="", pod="aura-bot-<id>"})
An example of this panel is shown below:

Container memory
Container memory panel shows a time series with the current memory consumption the selected container. It also shows the current, maximum, minimum and average memory consumption of the container.
The x-axis shows the time series and the y-axis shows the amount of memory consumed by the container.
The queries used to get the panel information are:
sum(kube_pod_container_resource_requests_memory_bytes{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"})
sum(kube_pod_container_resource_limits_memory_bytes{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"})
sum(container_memory_working_set_bytes{namespace="aura-<dev>",container!="POD",container!="",pod!="", pod="aura-bot-<id>",container="aura-bot"}) by (container)
An example of this panel is shown below:

Pod network
Pod network panel shows a time series with the current I/O network consumption of the selected pod. It also shows the current, maximum, minimum and average network consumption of the pod.
The x-axis shows the time series and the y-axis shows the amount of bytes consumed by the pod.
The queries used to get the panel information are:
sum(rate(container_network_receive_bytes_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m]))
sum(rate(container_network_transmit_bytes_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m]))
An example of this panel is shown below:
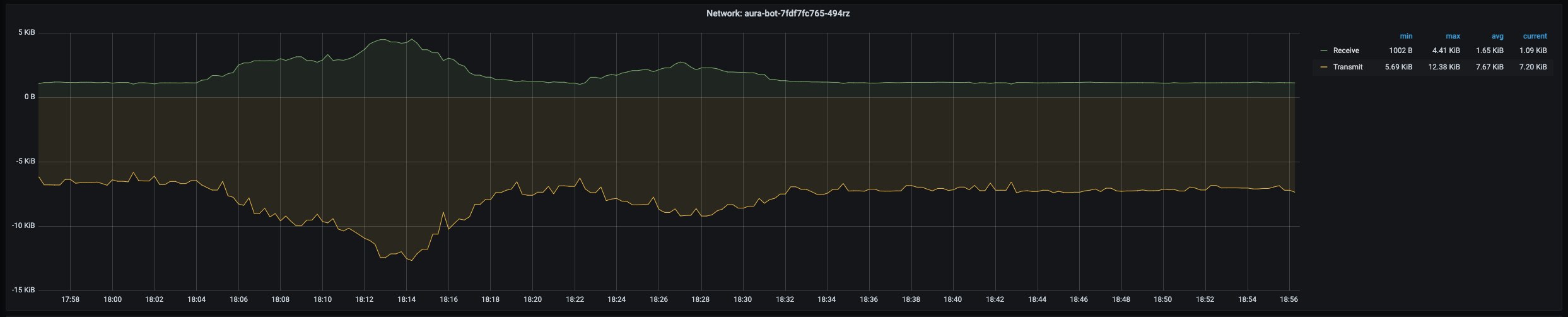
Pod CPU
Pod CPU panel shows a time series with the current CPU consumption of the selected pod. It also shows the current, maximum, minimum and average CPU consumption of the pod.
The x-axis shows the time series and the y-axis shows the percentage of CPU used by the pod.
The queries used to get the panel information are:
sum(kube_pod_container_resource_requests_cpu_cores{namespace="aura-<env>",pod="aura-bot-<id>"})
sum(kube_pod_container_resource_limits_cpu_cores{namespace="aura-<env>",pod="aura-bot-<id>"})
sum(rate(container_cpu_usage_seconds_total{namespace="aura-<env>",container!="POD",container!="",pod!="", pod="aura-bot-<id>"}[1m]))
An example of this panel is shown below:
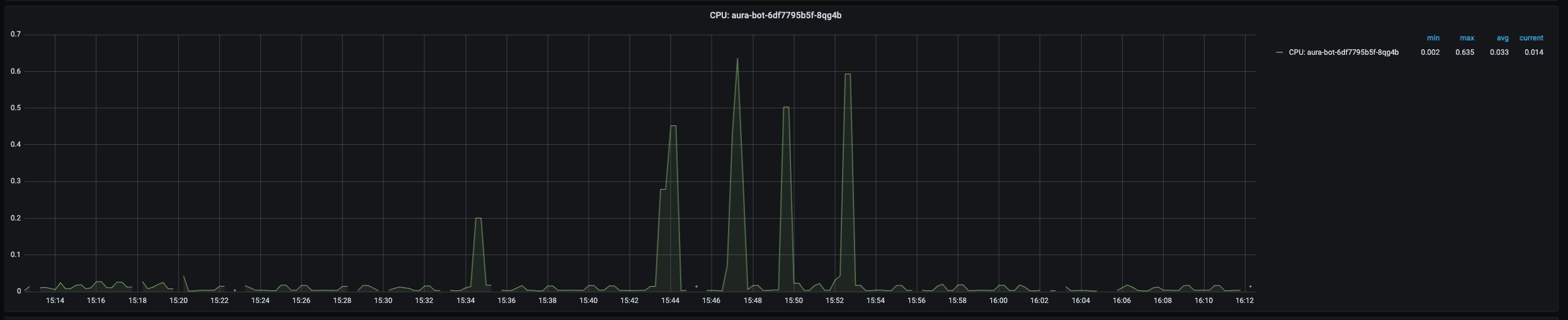
Container CPU
Container CPU panel shows a time series with the current CPU usage of the selected container within the pod. It also shows the current, maximum, minimum and average CPU usage of the container.
The x-axis shows the time series and the y-axis shows the percentage of CPU used by the container.
The queries used to get the panel information are:
sum(kube_pod_container_resource_requests_cpu_cores{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"})
sum(kube_pod_container_resource_limits_cpu_cores{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"})
sum(rate(container_cpu_usage_seconds_total{namespace="aura-<env>",container!="POD",container!="",pod!="", pod="aura-bot-<id>",container="aura-bot"}[1m]))
An example of this panel is shown below:

Container disk
Container Disk panel shows a time series with the current disk usage of the selected container within the pod. It also shows the current, maximum, minimum and average disk usage of the container.
The x-axis shows the time series and the y-axis shows the amount of disk used by the container.
The queries used to get the panel information are:
sum(rate(container_fs_reads_bytes_total{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"}[1m])) by (container,device)
sum(rate(container_fs_writes_bytes_total{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"}[1m])) by (container,device)
An example of this panel is shown below:

Pod network errors
Pods network errors panel shows a time series with the percentage of errors in network access of the pod. It also shows the current, maximum, minimum and average number of errors of the pod, related to errors while receiving and transmitting data to the network.
The x-axis shows the time series and the y-axis shows the percentage of errors of the pod network accesses.
The queries used to get the panel information are:
sum(rate(container_network_receive_packets_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) / sum(rate(container_network_receive_errors_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) * 100
sum(rate(container_network_receive_packets_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) / sum(rate(container_network_receive_packets_dropped_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) * 100
sum(rate(container_network_transmit_packets_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) / sum(rate(container_network_transmit_errors_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) * 100
sum(rate(container_network_transmit_packets_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) / sum(rate(container_network_receive_packets_dropped_total{namespace="aura-<env>",pod="aura-bot-<id>"}[5m])) * 100
Pod status
This section consists of 5 panels: ready, created, number of restarts, last terminated reason, waiting reason and the description of the image running in the container.
Ready
Ready panel shows a time series with heartbeat of the container. If there are no errors, it should be a flat line in 1.0.
The x-axis shows the time series and the y-axis shows the answer of the heartbeat of the container: 1 is a correct answer.
The queries used to get the panel information are:
kube_pod_container_status_ready{namespace="aura-<env>",pod="aura-bot-<id>",container="aura-bot"}
An example of this panel is shown below:

Pod created
Pod created panel shows the timestamp when the selected pod was created.
The queries used to get the panel information are:
kube_pod_created{namespace="aura-<env>",pod="aura-bot-<id>"} * 1000
An example of this panel is shown below:

Last terminated reason
This panel shows the reason why the pod entered the terminated status.
Last waiting reason
This panel shows the reason why the pod entered the waiting status.
Info
Info panel shows the images running in the containers of the selected pod.
The queries used to get the panel information are:
kube_pod_container_info{namespace="aura-<env>",pod="aura-bot-<id>"}
An example of this panel is shown below:
