This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
ATRIA capabilities
ATRIA capabilities
Discover the AI-driven functionalities that the ATRIA platform put at your disposal for the generation of experiences.
They are primarily focused on improving the understanding of human language and, consequently, providing highly reliable responses to the user in a secure and controlled manner.
Additionally, access documentation regarding available key ATRIA features.
ATRIA AI-driven functionalities
ATRIA is conceived as an AI technologies aggregator and currently includes key capabilities, based both on proprietary and third-party technologies.
The current capabilities and AI technologies in this first ATRIA are shown in the following figure and introduced below.
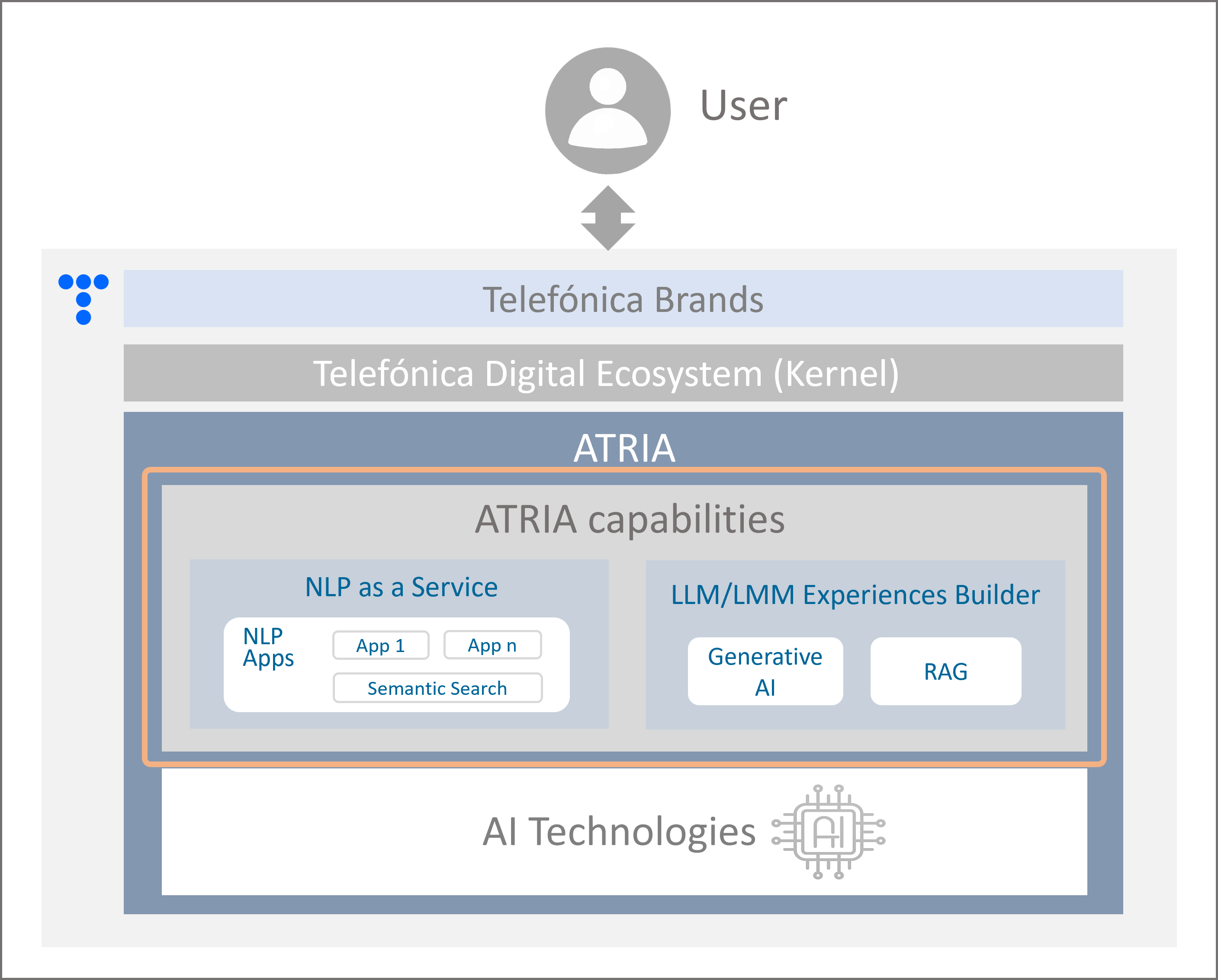
Figure 3. ATRIA capabilities
NLP as a Service
NLP as a Service enables the connection with Aura cognitive services to leverage different NLP technologies via API for understanding users’ requests and providing accurate responses.
Find detailed information regarding NLP as a Service or access directly to its associated capabilities:
LLM/LMM Experiences Builder
The LLM/LMM Experiences Builder allows ATRIA to integrate third-party AI technologies via API to create interactive, personalized, and dynamic user interactions while establishing control mechanisms to ensure security and data privacy.
Find detailed information regarding the LLM/LMM Experiences Builder or access directly to its associated capabilities:
ATRIA features
Additionally, ATRIA contains key features focused on improving the generation of experiences, that allow advanced customization options and adaptability to user preferences.
-
Multibrand feature: Users can access ATRIA through the different Telefónica brands available in their country.
-
Multi-language feature: ATRIA RAG includes a multi-language feature, to deliver service to a global audience in multiple languages, as it automatically detects the input language and provides the response accordingly.
1 - NLP as a Service
NLP as a Service
Discover NLP as a Service, the AI-driven functionality for seamless language recognition and integration based on Natural Language Processing technologies
Introduction to NLP technologies
Natural language processing (NLP) refers to the branch of AI concerned with giving computers the ability to process, understand and generate human language. NLP combines computational linguistics (rule-based modelling of human language) with statistical, machine learning and deep learning models to bridge the communication gap between humans and machines.
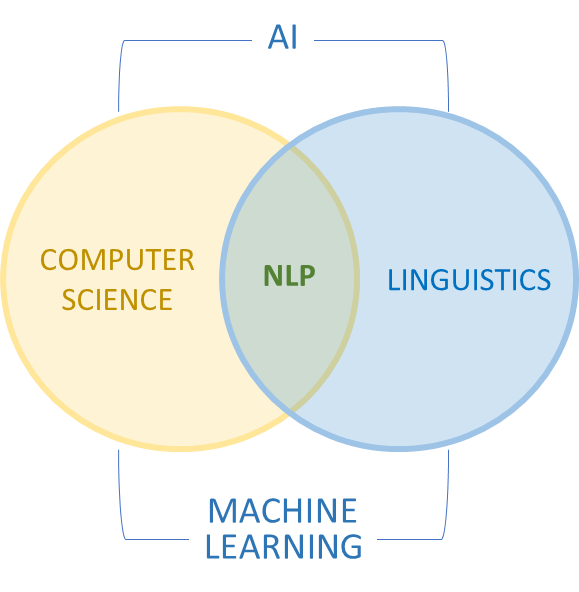
Figure 4. NLP technologies
NLP encompasses a wide spectrum of technologies designed to be integrated into diverse user experiences. It includes deterministic and probabilistic techniques, syntax and semantics methods, named entity recognition (NER), etc.
Nowadays, the use of NLP in virtual assistants is not limited to understand and respond to simple utterances but also to derive meaning and use data behind user queries, allowing them to provide relevant and precise responses resulting in more accurate and natural interactions through different NLP technologies.
Application of NLP as a Service in ATRIA
NLP as a Service enables the use of different technologies through NLP Apps (Natural Language Processing recognition stages) for understanding users’ requests and providing back accurate responses.
Currently, these technologies, both proprietary and third-party ones, are included in the Aura NLP component but, in future releases, external NLP methods will be used.
In this framework, constructors have two approaches depending on the utilized stages:
-
Using NLP Apps (NLP recognition stages) different from Semantic Search
Find here detailed information regarding NLP Apps capability
-
Using Semantic Search technology, a specific NLP App that overcomes traditional keyword-based searches through the use of embeddings.
Find here detailed information regarding Semantic search functionality
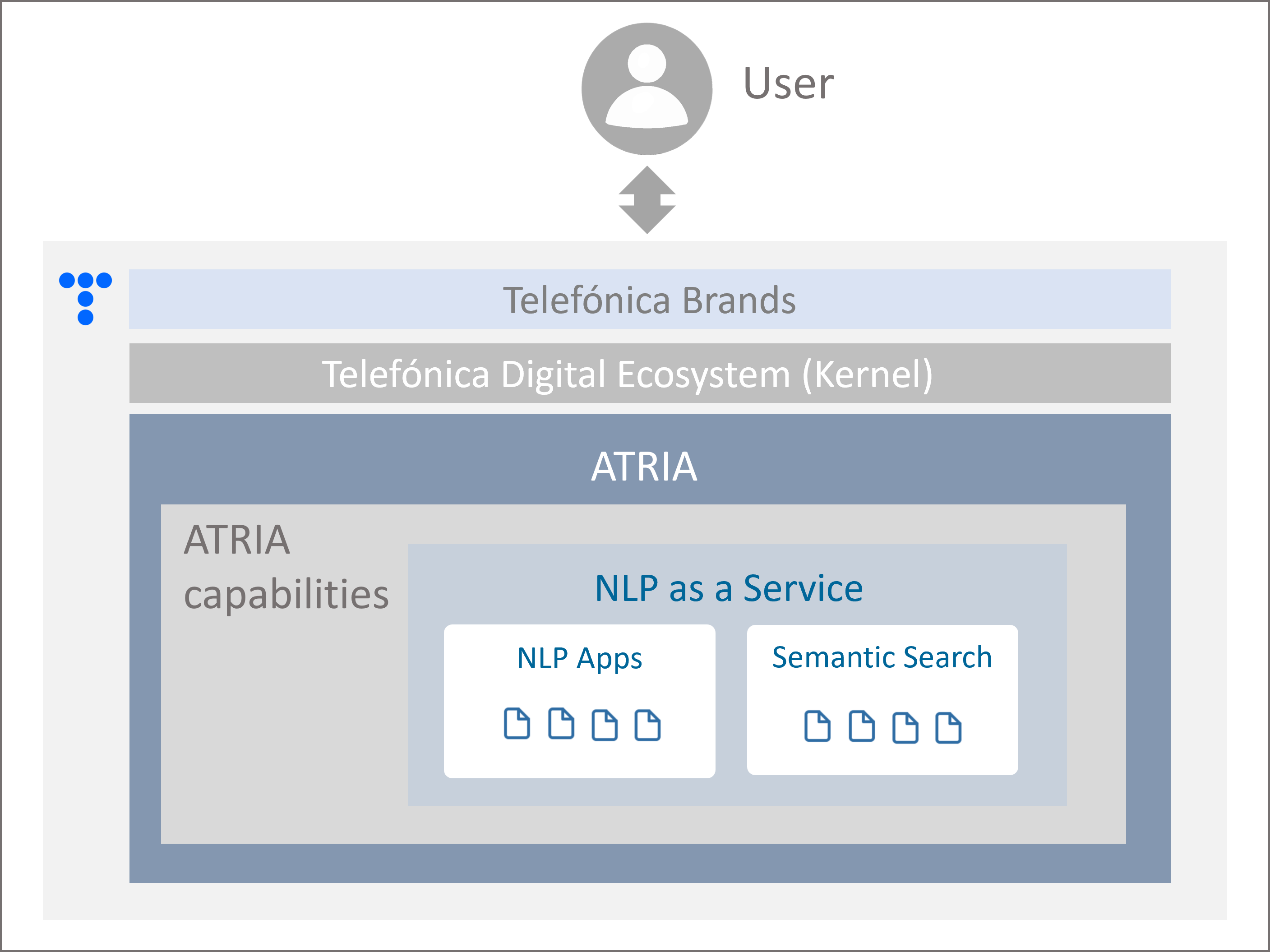
Figure 5. NLP as a Service in ATRIA
Benefits from the use of NLP as a Service
NLP as a Service offers several benefits both for constructors and end-users:
Benefits for use cases constructors
- Less time and complexity of use cases development
- It is possible to create and configure tailored NLP pipelines, choosing from a variety of available stages and connectors that cover different aspects of Natural Language Processing.
- No need for the manual generation of training phrases (aliases) for generic questions knowledge bases.
- Knowledge bases can be updated continuously in an easy and quick way.
- Accessibility: any application, both internal and external to Aura Platform, can consume this service.
Benefits for Aura end users
- End-users can interact with Aura in a natural and conversational way, using their own words and expressions and even informal language, slang, abbreviations, misspellings, etc.
- Improved Aura’s understanding capabilities, leading to fast and reliable responses and results.
- Easy update of the knowledge bases, so the users can receive reliable responses based on up-to-date data.
- The NLP service can be leveraged as capabilities offered to end-users or as internal features used by other Telefonica teams in order to streamline specific internal processes.
1.1 - NLP Apps
NLP Apps capability
Overview of the NLP Apps capability, encompassing the underlying technology and its application in ATRIA
Introduction to NLP Apps technology
Within Natural language processing (NLP) technologies, NLP Apps refers to NLP pipelines (chains) that combine different technologies for language processing with several tools for combining them.
Currently, these technologies, both proprietary and third-party ones, are included in the Aura NLP component and can be categorized in the following groups:
The technical description of all the available NLP technologies in included in the document Components for NLP pipelines
Application of NLP Apps in ATRIA
ATRIA enables the generation of experiences (use cases) through the use of Aura cognitive capabilities as stand-alone NLP Apps for sending a request expressed in natural language and receiving back an accurate response without the need for a conversational bot.
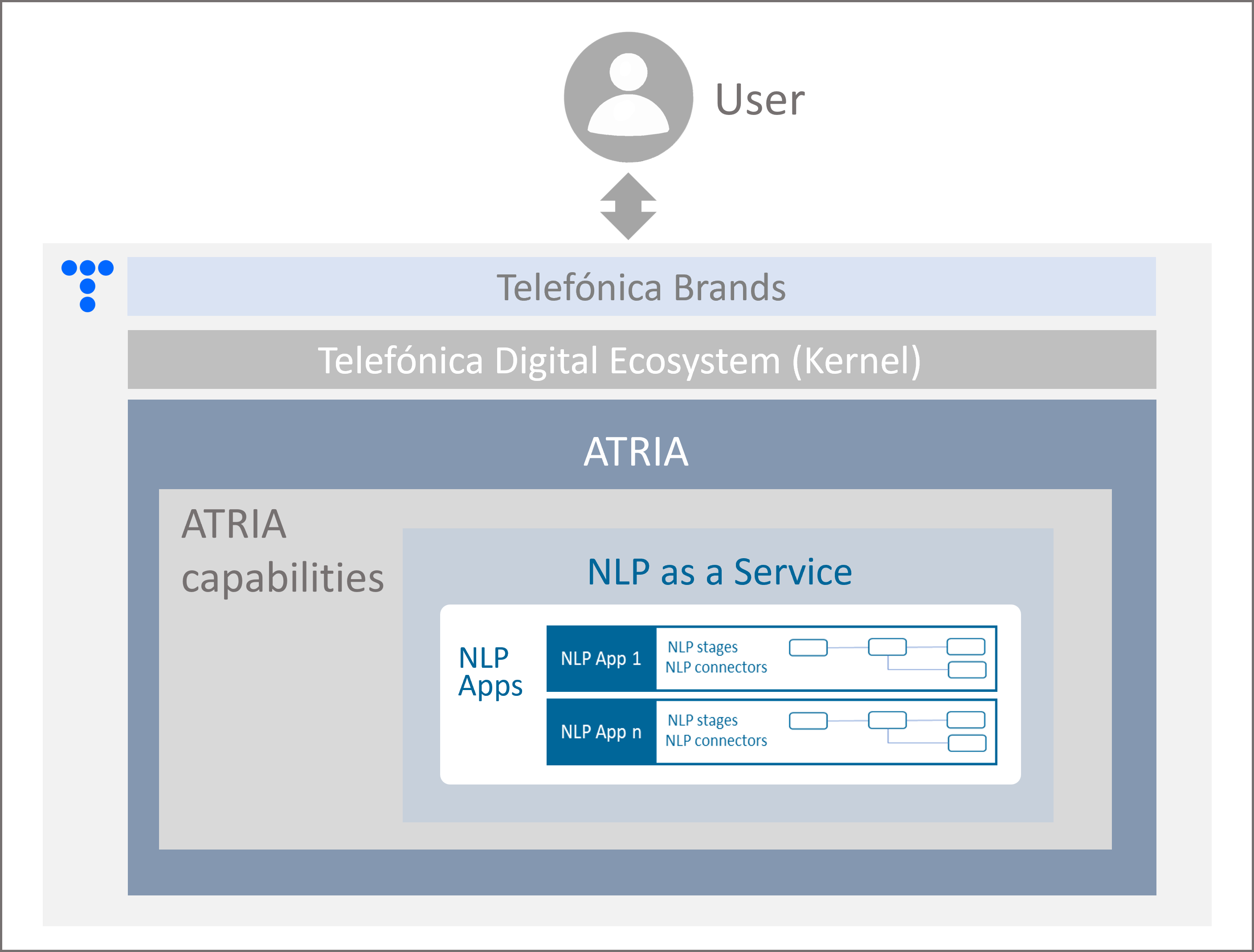
Figure 6. NLP Apps in ATRIA
Interaction with NLP Apps in ATRIA
This service is accessible via API, enabling its consumption both from Aura Platform or any external application.
Functional overview
A simple overview of the process is provided below:
-
A user sends a request to ATRIA, indicating which specific NLP App she wants to use for the recognition of the request. These Apps are available in Aura NLP, a module of Aura Cognitive Services in charge of processing and understanding human natural language.
-
The NLP technologies in the pre-selected specific App resolves the use case and generates a response.
-
The response is sent back to the user.
1.2 - Semantic Search
Semantic Search capability
Overview of the Semantic Search capability, encompassing the underlying technology and its application in ATRIA
Introduction to Semantic Search technology
Within Natural Language Processing technologies, Semantic Search goes beyond the traditional keyword-based search methods, as it delves into the intent and the meaning behind a query, interpreting the meaning of words and phrases.
This leads to the generation of more accurate and relevant search results that align closely with the user’s intent.
For this purpose, semantic search uses neural network embeddings: a representation of words or phrases in a continuous vector space that captures the semantic relationships between them. This information is crucial for semantic search to interpret the user’s intent accurately.

Figure 7. Semantic Search technology
Application of Semantic Search in ATRIA
Semantic Search is a specific NLP App, included in the NLP as a Service capability.
ATRIA benefits from the Semantic Search capability based on embeddings for the development of generic questions experiences (grounded in FAQs).
It allows achieving an accurate understanding of requests and the generation of highly reliable answers, fully aligned with the user's expectations.
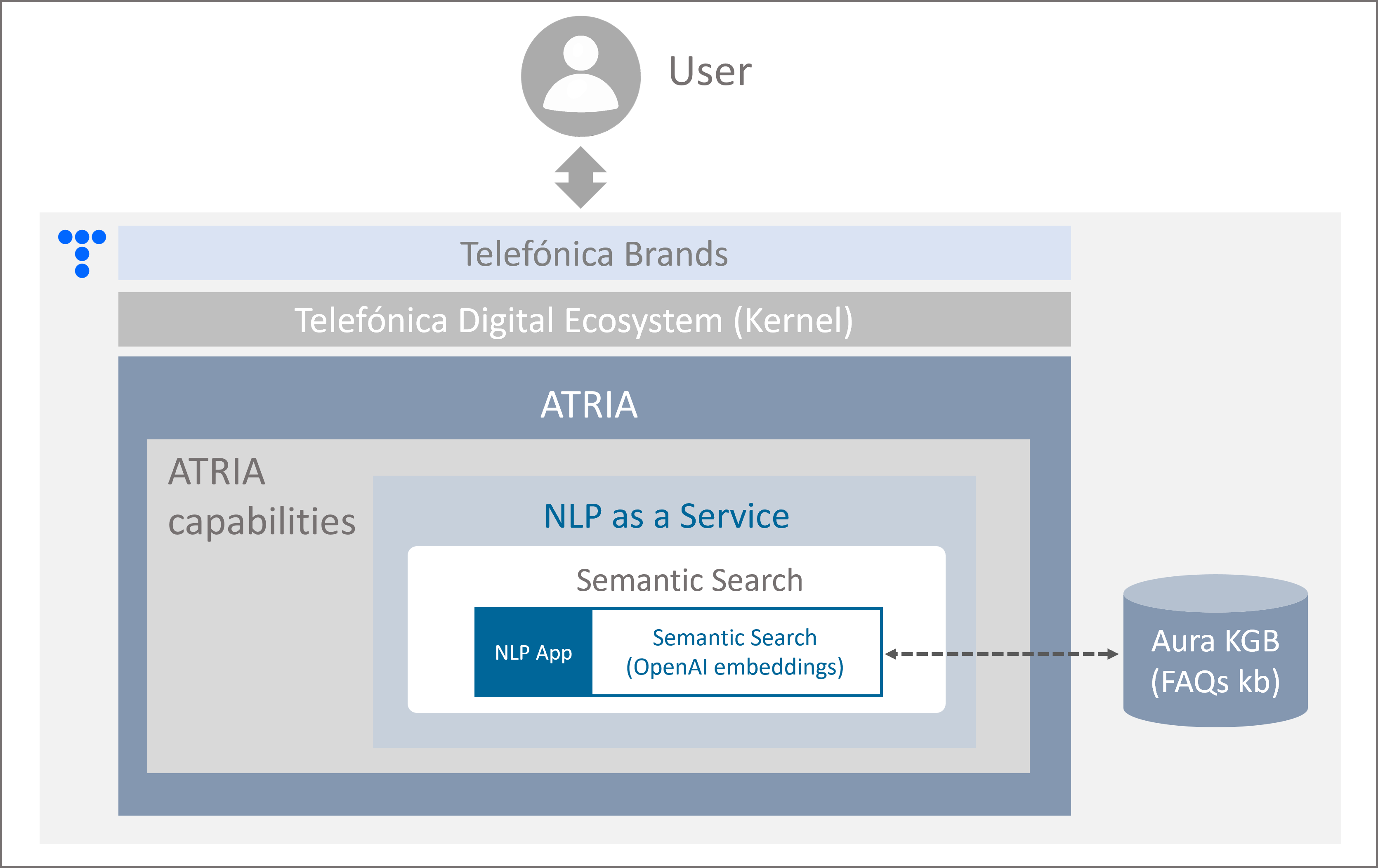
Figure 8. Semantic Search in ATRIA
Interaction with Semantic Search in ATRIA
This service is accessible via API, enabling its consumption both from Aura Platform and any external application.
Semantic search technology is available in Aura through a specific Aura NLP stage: OpenAI embeddings.
Current available models
Semantic Search currently uses Azure OpenAI embeddings technology.
Check the version of the model here.
Functional overview
The use of this capability encompasses three different stages:
-
Preparation, for the creation of the use case knowledge bases with the required FAQs and associated answers, and the subsequent generation of embeddings with this information.
-
Identification, in which a user sends a request to ATRIA, selecting as the specific NLP App the one that includes the semantic search technology (OpenAI embeddings). This app recognizes the user’s request.
-
Answer generation: the best response to the user request is identified and sent back to the user.
2 - LLM/LMM Experiences Builder
LLM/LMM Experiences Builder
Discover ATRIA LLM/LMM Experiences Builder, that includes LLM chains for the generation of different types of content through Generative AI or RAG technologies
Introduction
ATRIA can integrate third-party AI technologies via API through the LLM/LMM Experiences Builder to create interactive, personalized, and dynamic user interactions, while establishing control mechanisms to ensure security and data privacy.
To do that, the LLM/LMM Experiences Builder allows the creation of LLM chains, which are defined as structured workflows that involve several interconnected steps, each of them using diverse LLM technologies to process, generate, or transform text data. Each step feeds into each other, with the ultimate goal of understanding a request expressed in natural language and providing an accurate response to it.
In the current release, two predefined LLM chains are included in ATRIA, offering two key capabilities:
-
Simple flows that call to an LLM: Generative AI capability for understanding and generating human-like texts through LLMs.
-
Complex flows: General RAG capability through RAG (retrieval-augmented-generation) processing techniques that combine different AI models.
Currently, only these two predefined chains can be used. In further ATRIA versions, constructors will have the flexibility of creating customized LLM chains.
ATRIA also includes a testing UI interface to test the behavior of the LLM/LMM Experiences Builder when using both Generative and RAG capabilities, before publishing into production. In further versions, the solution will include an interface to configure different parameters easily and a mechanism to load data.
Functional components
The following diagram schematically shows the functional components into play in the LLM/LMM Experiences Builder.
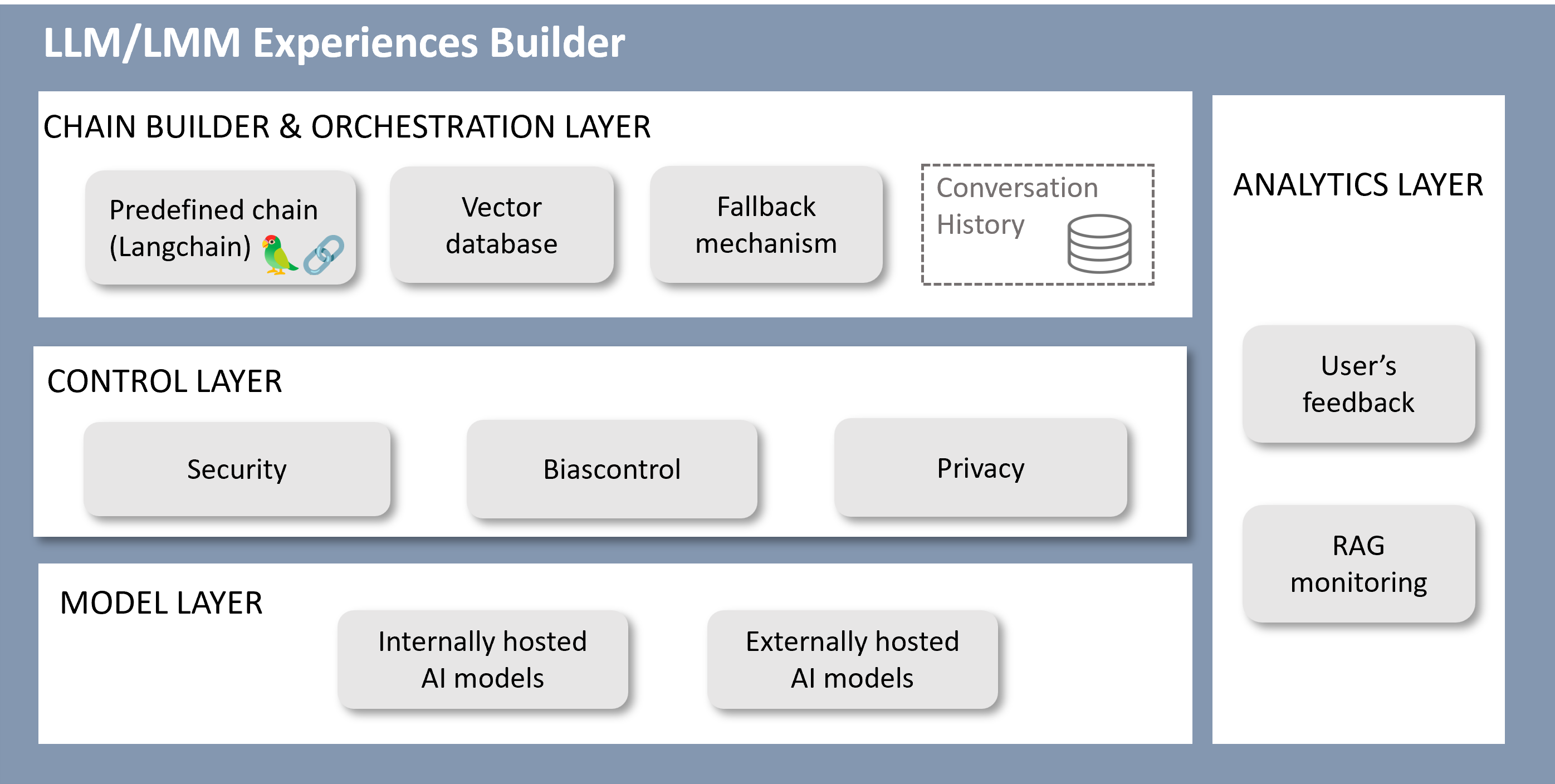
Figure 9. LLM/LMM Experiences Builder
Chain builder and orchestration layer
Currently, this layer allows:
- Using a predefined LLM chain for specific use cases, that corresponds to a RAG (Retrieval Augmented Generation) pipeline integrated using LangChain.
- Manual configuration of parameters.
- Integration of new components (vector databases, document loaders, text splitters, etc.) by Aura Global Team.
- Simple fallback mechanism: flag set in configuration.
- Conversation history, taking into account past interactions for the enrichment of responses.
Control layer
The components of this layer have the following roles:
- Providing mechanisms for ensuring security and data protection.
- Heuristics blacklists.
- Prompt injection.
- Templates.
- Including the control of tokens consumption.
Model layer
The model layer can include both internally and externally hosted models.
Models currently integrated into ATRIA
The AI models currently integrated in ATRIA are:
-
Azure OpenAI embeddings model: text-embedding-ada-002
-
Hugging face models: paraphrase-multilingual-MiniLM-L12-v2, Multi-qa-distilbert-cos-v1
-
Azure OpenAI GPT models: gpt-4-turbo, gpt-4o, gpt-4o-mini, o3-mini
In further releases, the model manager will integrate other state-of-the-art models from different providers, avoiding lock-in and making easy for constructors to choose, try and select the one that fits better with their needs.
Analytics layer
The analytics layer currently includes two features:
-
Feedback functionality, for the estimation of the accuracy in the response, in which the user can provide feedback by clicking on a thumbs-up icon if the quality and appropriateness of the answer is correct or selecting the thumbs-down icon if the response misses the point, contains hallucinations, or is unclear.
-
Simple RAG monitoring to check how the RAG chain performs.
2.1 - Generative AI
Generative AI capability
Overview of the Generative AI capability, encompassing the underlying technology, its application in ATRIA and the benefits derived from its use
Introduction to Generative AI
What is Generative AI?
Generative Artificial Intelligence is a subset of Machine Learning that focuses on the creation of new content, such as text, images, or music, based on patterns learned from large volumes of data.
This technology has advanced significantly in recent years, fueled by the development of Deep Learning models that can understand and replicate complex data structures.
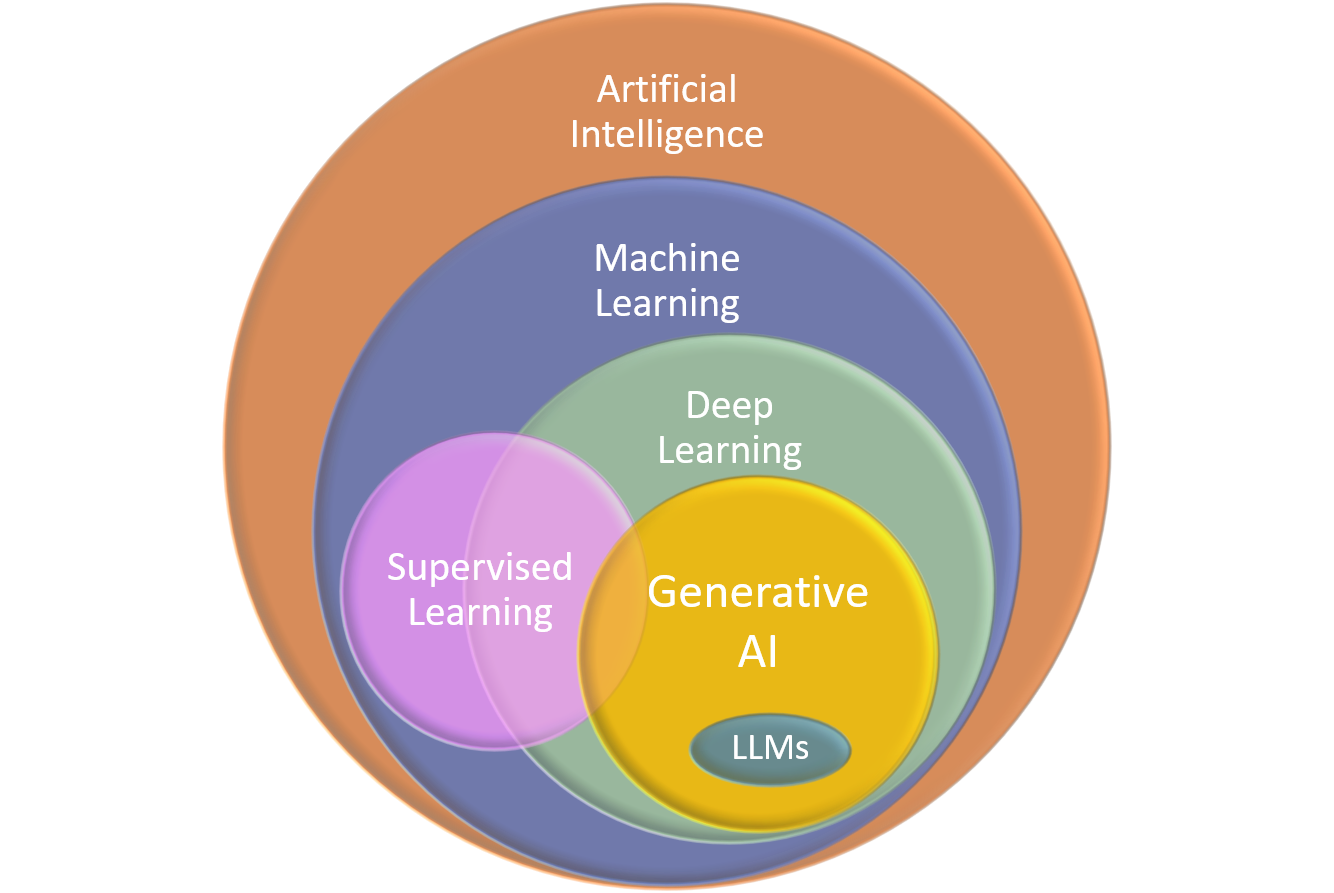
Figure 10. Generative AI technology
Below are the main steps in how Generative AI works:
-
Training: The model is fed with extensive datasets containing examples of the target content, allowing the system to identify patterns, structures and relationships among different elements.
-
Instruction input: The user provides an instruction or “prompt,” which can be a question, a topic, or any indication of what is expected from the model output.
-
Content generation: Based on the information obtained during training, the model applies complex algorithms to generate a relevant and coherent response or new content aligned with the user’s request.
-
Response delivery: The model presents the generated output to the user quickly and efficiently. It can be a text, an image, or any other type of content.
Within Generative AI, the Large Language Models (LLMs) are advanced AI models designed to understand and generate human-like text, typically trained on vast amounts of text data, enabling them to predict and produce coherent and appropriate text. They are the ones integrated into ATRIA.
Benefits and limitations
The main benefits from the use of Generative AI are summarized below:
- Creativity and Originality: Generative AI generates new and original content that can inspire creators.
- Efficiency: Generative AI automates content generation tasks, allowing humans to focus on more complex activities.
- Personalization: Generative AI generated content is tailored to the specific needs of users.
- Access to information: Generative AI provides quick answers to complex questions thanks to its extensive access to data.
Despite these advantages, Generative AI has certain limitations that led ATRIA to integrate other complementary technologies:
- Hallucinations: Generative AI can generate inaccurate responses that seem plausible, leading to misinformation.
- Temporal Limitations: Generative AI models are limited to the information available at the time of their last training, meaning they cannot access real-time or recent data updates.
Application of Generative AI in ATRIA
Generative AI is a key ATRIA capability provided by a predefined chain designed with the LLM/LMM Experiences Builder.
ATRIA enables the generation of experiences (use cases) to resolve users' requests expressed in natural language by supporting simple calls to AI models.
This is done through an easy integration of advanced Generative AI technologies while guaranteeing security and privacy in interactions.

Figure 11. Generative AI in ATRIA
Example case
Imagine that our platform, ATRIA, operates like a restaurant with different chefs, each specialized in a unique approach to meeting customers' needs.
A traditional generative model can be compared to Chef Manuel, a chef who spent several years mastering in traditional Spanish cuisine.
Manuel’s expertise encompasses a wide range of recipes and cooking techniques, but some of his knowledge may be outdated since he hasn’t pursued further training in recent years.
When a customer requests for a nutritious and hearty meal, Manuel relies solely on his internal knowledge to prepare a classic dish: lentils with vegetables. He does not need to search for additional information because his prior expertise is sufficient to offer a consistent and reliable answer.
A traditional generative model operates like Manuel, generating responses based solely on the implicit knowledge learned during the model's training, without consulting external sources.
Interaction with ATRIA Generative AI
This service is accessible via API, enabling its consumption both from Aura Platform and any external application.
Current available models
The AI-driven models currently integrated into ATRIA are included here.
Functional overview
The use of this capability encompasses different stages:
-
When a user sends a request to ATRIA, it is sent to an auto-generative content generator, the one that best aligns with the use case considering different factors such as latencies, costs, etc.
-
Additionally, specific instructions upon which the model must base its response are also included. These instructions can be configured to meet specific channel-level business and experience requirements but, at the same time, to ensure that the provided responses retain the nuances of tone and personality that characterize Aura.
-
In addition, ATRIA provides a layer of security to avoid prompt injection, that is, to prevent misuse by third-party services that can create malicious prompts as inputs and cause the model to act in unintended ways.
For example, it can prevent a user from modifying the instructions on how the system should behave or the invalidation of instructions from a predefined block of the prompt (Aura personality), if contradictory instructions are given.
-
The Generative AI model recognizes the request and generates the most appropriate response for it. This response is sent back to the user.
Benefits from the use of Generative AI in ATRIA
There are clear benefits derived from the integration of Generative AI in ATRIA:
Benefits for constructors
- It streamlines the use cases development process, since there is no need to generate specific responses or undergo specific trainings.
- Other types of experiences, not directly related to Aura, can be generated. For example: data analysis tasks, development of new products, etc.
Benefits for end-users
- Our customers’ satisfaction will increase, as Aura can offer enhanced understanding capabilities.
- Aura can incorporate new areas of interest for users in a more agile manner and explore new types of users for whom to develop services based on natural language recognition technologies.
- ATRIA interactions guarantee security and privacy for our users.
Generative feedback functionality
When testing how Generative AI/RAG capabilities work with the ATRIA web interface aura-manager, it is possible to use the feedback functionality to estimate the user’s satisfaction regarding the quality and appropriateness of the generated answer to her request. This can be done easily by clicking the thumbs-up or thumbs-down icons.
2.2 - RAG
RAG capability
Overview of the RAG capability, the benefits derived from its use and the current predefined RAG chain in ATRIA
Introduction to RAG technology
RAG (Retrieval Augmented Generation) is a technique for augmenting LLM knowledge with additional data. It provides a way to optimize the output of an LLM with targeted and updated information without retraining it; thus, providing more appropriate answers based on specific and latest data.
The process includes three differentiated parts:
- Retrieval: it searches and extracts relevant information from a KB database using information retrieval techniques, such vector representations (embeddings) to find text blocks that contain the appropriate information to resolve the input request.
- Augmented: the RAG model augments the user input (or prompts) by adding the relevant retrieved data. This step uses prompt engineering techniques to communicate effectively with the LLM.
- Generation: the enriched prompt is sent to an LLM, that generates the most accurate response for the user.
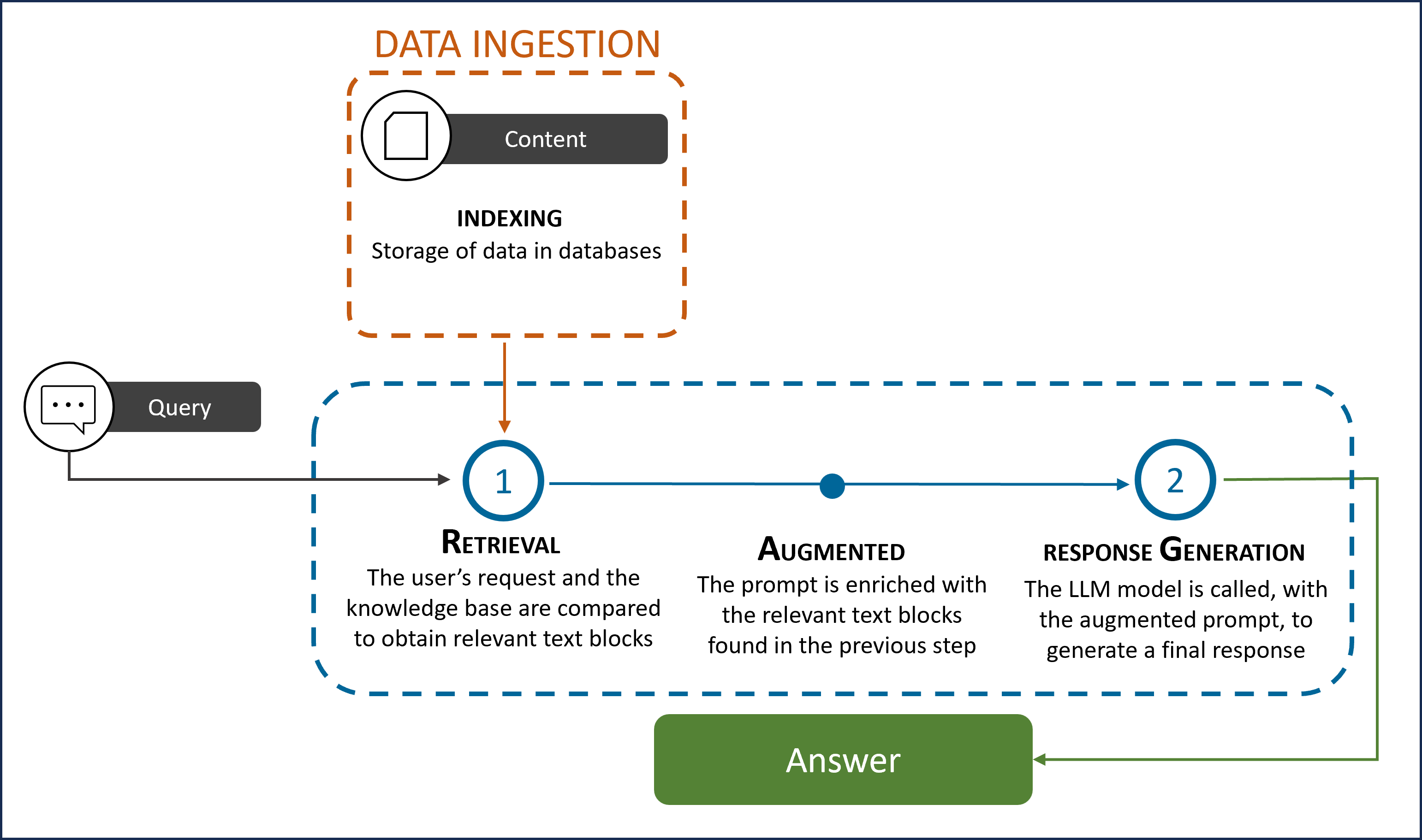
Figure 12. RAG technology
Application of RAG in ATRIA
As explained before, the LLM/LMM Experiences Builder enables the generation of LLM chains that integrate different AI technologies.
Within this capability, complex flows based on the RAG technology can be integrated.
Example case
Imagine that our platform, ATRIA, operates like a restaurant with different chefs, each specialized in a unique approach to meeting customers' needs.
A RAG model can be compared to Chef Sara, a chef who combines her traditional culinary experience with the real-time consultation of resources to enhance her recipes with the latest culinary trends worldwide, as she likes to be continuously up-to-date.
When a customer requests a nutritious and hearty meal, Sara goes beyond her own knowledge, based on already learnt techniques and recipes. Instead, she consults innovative cuisine resources: Indian cookbooks and her recent notes on advanced molecular cooking techniques. These external sources allow her to innovate and propose a unique dish: a curry foam, light and airy, with an intense spice flavor and a touch of coconut milk.
In technical terms, the RAG approach combines:
a. Generation based on prior knowledge (the internal model): equivalent to Sara's knowledge of cooking.
b. Real-time retrieval of external information: consulting cookbooks and notes represents how a RAG system looks up information in databases or dynamic sources during the response process.
This integration allows the model to provide more contextualized responses, tailored to specific needs, especially when the stored knowledge is limited or insufficient.
Currently, ATRIA incorporates the following RAG chains:
In upcoming versions, constructors will be able to design their own LLMs chains based on RAG.
Benefits from the use of RAG technologies
-
Updated and targeted information: RAG allows developers to provide the latest data to the generative models, targeted to the specific use case.
-
Cost-effective implementation: Data in the knowledge repository can be continually updated without incurring significant costs.
-
Enhanced user trust: The data sources contributing to the RAG’s vector database are identifiable. This transparency allows for the correction or removal of any inaccuracies present in RAG and clearly improves users’ confidence.
-
Improved developers control: With RAG, developers can test and improve their applications more efficiently, control and change the LLM’s information sources to adapt to changing requirements, restrict sensitive information retrieval to different authorization levels and ensure the LLM generates appropriate responses.
2.2.1 - General RAG
General RAG capability
Overview of the General RAG capability, encompassing the underlying technology, its application in ATRIA and the benefits derived from its use
Application in ATRIA: General RAG
ATRIA enables the generation of generic questions experiences (use cases) to resolve users' requests expressed in natural language and based on FAQs by supporting complex calls to AI models.
This is done through the integration of a predefined RAG (Retrieval Augmented Generation) chain while guaranteeing security and privacy in interactions.

Figure 13. General RAG in ATRIA
The predefined RAG chain defined in ATRIA is called General RAG. It includes additional steps that overcome the potential of Retrieval Augmented Generation technologies by optimizing the input prompt and generating more accurate responses. See details in section Functional overview.
In upcoming versions, constructors will be able to design their own LLMs chains based on RAG.
Interaction with ATRIA General RAG capability
This service is accessible via API, enabling its consumption both from Aura Platform and any external application.
Current available models
The AI-driven models currently integrated into ATRIA are included here.
Functional overview of General RAG
The use of the General RAG capability encompasses three different stages:
-
Data ingestion, that includes uploading the knowledge bases used for lexical (keywords) and semantic search (embeddings) search.
Discover the underlying processes for that in the document Import documents into *ATRIA, as well as tips for data curation, a process recommended before the documents uploading.
-
RAG chain: If a request enters ATRIA, the General RAG capability executes the predefined steps in its chain, which are described in the following figure.
-
Aura answer: The generated response is sent to the user.
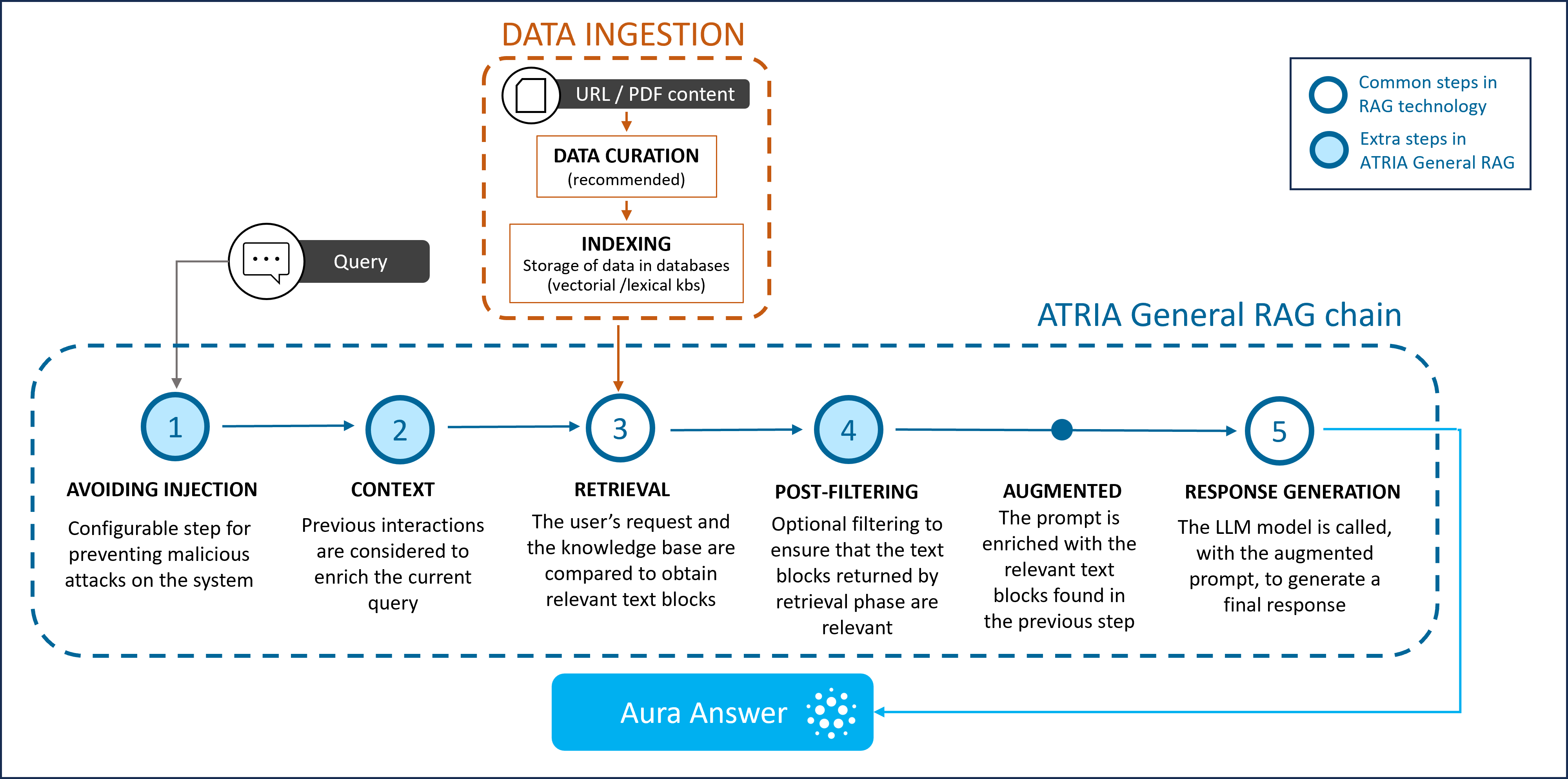
Figure 14. General RAG stages
Making a zoom in the stages of the General RAG pipeline, the following steps are included:
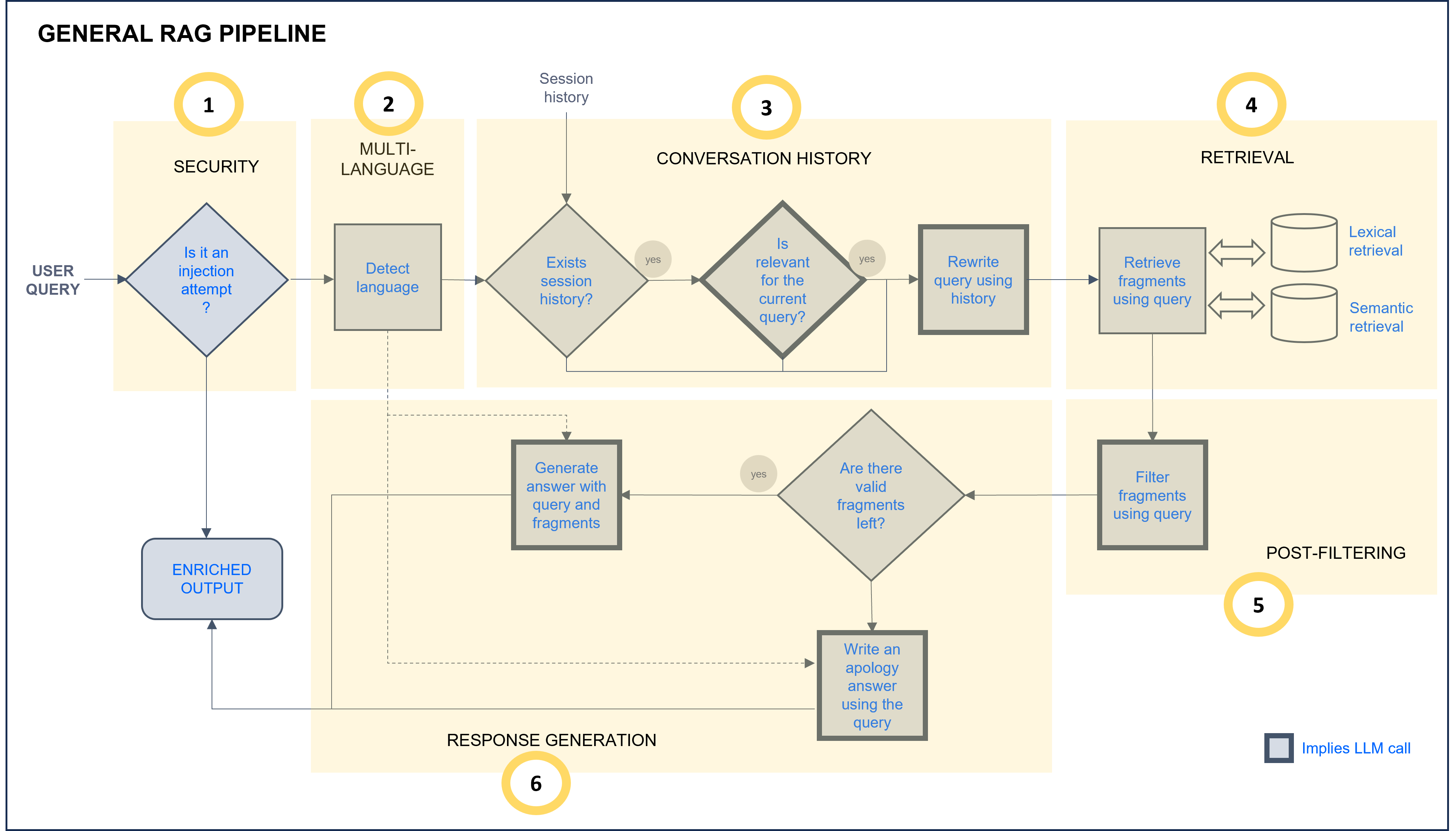
Figure 18. General RAG chain
- Security: the request is analyzed to improve security and prevent prompt injection.
- Multi-language: The multi-language feature allows users to receive responses in their own language. The system automatically detects the language in the user’s request in the multi-language step of the RAG pipeline, and this language is afterwards used in the response generation stage to provide the response back to the user.
- Conversation history: If there is information from previous interactions, they are now analyzed to check if they are relevant for the current query. In this case, the query is rewritten using this context information.
- Retrieval: Lexical and semantic retrieval from databases that return text blocks with key information to compose the response.
- Post-filtering: The retrieved text blocks are compared with the user query to determine if they are relevant or not to answer the question.
- Response generation: If so, the fragments are reordered and used to compose an augmented prompt which is resolved through LLMs technology.
Benefits from the use of ATRIA General RAG
-
The General RAG predefined chain enables all the advantages of RAG technologies to the resolution of use cases. Specifically for generic questions use cases based on FAQs.
-
Moreover, General RAG capability integrates other extra features that lead to more accurate responses:
- Features to avoid prompt injection
- Conversation history
- Filtering steps
-
The use of Retrieval Augmented Generation techniques enables the use of continually updated information, every time an up-to-date knowledge base is uploaded into the system.
Generative feedback functionality
When testing how Generative AI/RAG capabilities work with the ATRIA web interface aura-manager, it is possible to use the feedback functionality to estimate the user’s satisfaction regarding the quality and appropriateness of the generated answer to her request. This can be done easily by clicking the thumbs-up or thumbs-down icons.
Do you need a more detailed explanation on how Generative feedback capability works?
2.2.2 - Aura SQL RAG pipeline
Aura SQL RAG pipeline
Description of the SQL RAG pipeline
Introduction
ATRIA currently integrates one RAG pipeline for the conversion of a request from natural language to an SQL query.
Steps in the SQL RAG chain
The use of the SQL RAG chain encompasses different stages, which are explained and schematically represented below.
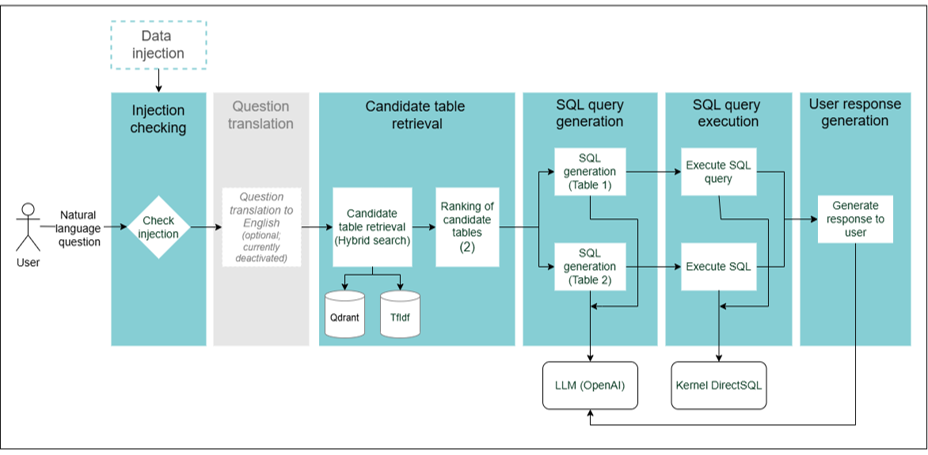
Figure 15. SQL RAG chain
1. Injection checking
- Detects the presence of anomalies in the user’s query that may affect the resolution process.
- Currently, a set of checks, based on heuristics, are made:
- Detects overly long questions.
- Detects suspicious substrings in the query.
2. Question translation (currently deactivated)
- Optional step for the translation of the user’s query into English.
- Currently, it is not activated.
3. Candidate table retrieval
- The system searches the candidate tables for relevant documents. This is currently done using a hybrid search, through the combination of lexical and semantic search (embeddings).
- The table retrieval is currently based on the similarity between the user’s query and the tables high level description.
4. SQL query generation
- The top-2 results (tables) are selected.
- In them, the user’s request is converted from natural language to an SQL query.
3 - ATRIA multibrand feature
Introduction to ATRIA multibrand feature
Description of ATRIA multibrand feature, based on a multitenant architecture
Introduction
ATRIA, just like Aura Virtual Assistant, is designed as a multibrand platform, meaning that users can access ATRIA through the different Telefónica brands available in their country.
This multibrand feature is based on a multitenant architecture, with a tenant defined as the deployment associated to a specific brand.
Functional multitenant architecture in ATRIA
An overview of the functional operation of the multibrand feature in ATRIA is shown and explained below:
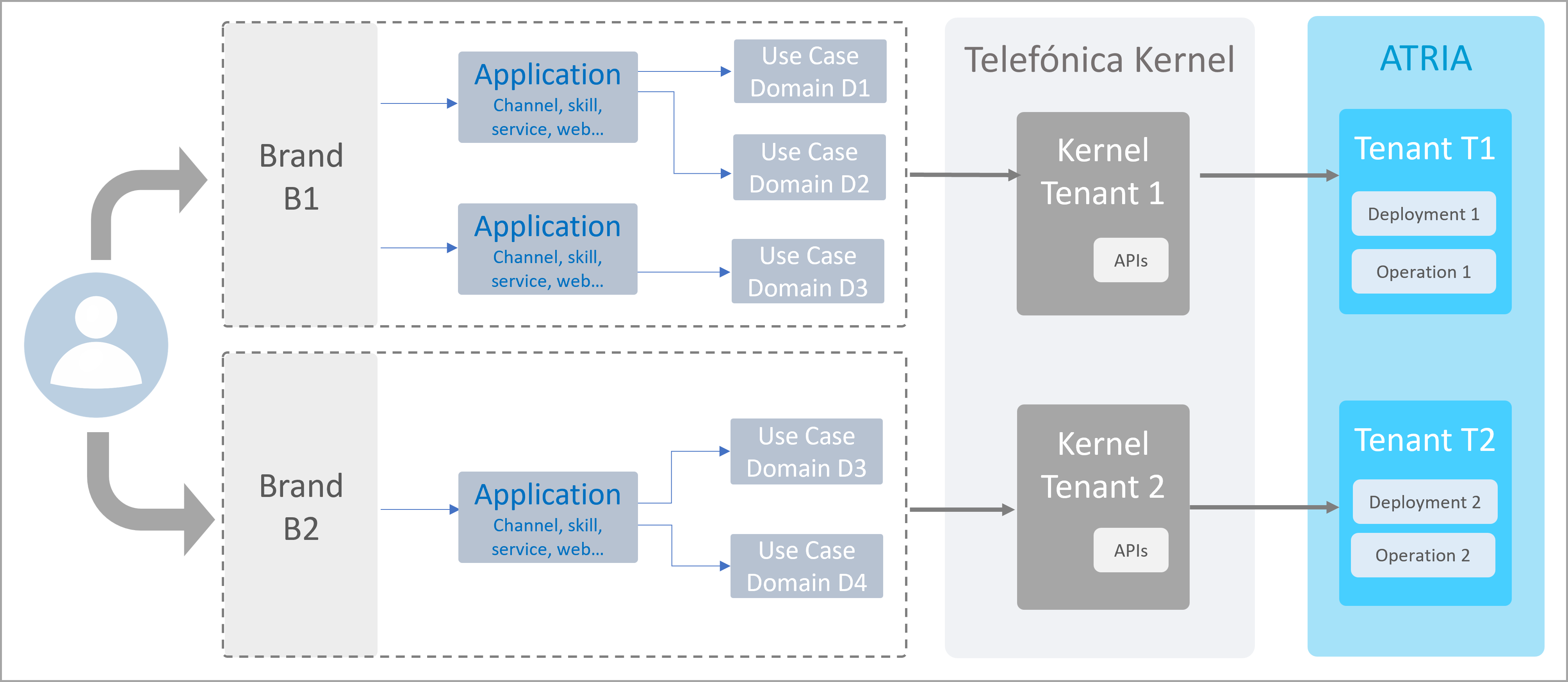
Overview of multitenant architecture in ATRIA
- ATRIA supports different brands
- Each brand is associated to several channels
- Each channel allows accessing to use cases in a specific domain
- When a user send a request, it passes through Kernel and is managed by a specific Kernel tenant
- This Kernel tenant sends the query to a particular ATRIA tenant
- ATRIA calls the required AI-driven models for its resolution
Technical documents
Multitenant configuration in Aura installer
Aura installer: Multitenant configuration: Guidelines for the configuration of different tenants when several brands are available in the OB.
Descriptive documents and guidelines
Once the user accesses through a specific Telefónica brand, the technical behavior of the corresponding Aura tenant is similar to the one before the implementation of the multitenant architecture. Therefore, there are no specific descriptive documents or guidelines for the multitenant architecture.
4 - ATRIA multi-language feature
Introduction to ATRIA multi-language feature
Description of ATRIA multi-language feature, offering its AI-driven capabilities in different languages
This feature is only available for ATRIA RAG stages
Introduction
ATRIA RAG now includes a multi-language feature, to deliver service to a global audience in multiple languages.
This multi-language capability allows users to make a request to ATRIA and receive back the response in their own language through a technology that automatically detects and adapts to the input language.
The multi-language feature provides multiple benefits:
- The information provided by ATRIA is easier to understand, as it is generated in the user’s language.
- A wide range of languages is supported, allowing ATRIA to reach a global audience.
- The user experience is also optimized by reducing the need for external translation tools, making communication more seamless and natural.
From a technical point of view, the model for text identification and classification fastText is used, that supports more than 176 languages.
Functional overview
This feature is only available for RAG stages
A high-level overview on how the ATRIA multi-language feature works is included below.
-
A users sends a request to ATRIA in a specific language. ATRIA automatically detects the input language and sends the response back to the user in the same language.
-
In case the user’s request includes a mixture of languages (for example, “por favor, dame feedback”), ATRIA detects the predominant language of the query and uses it in the response.
-
In case ATRIA is not capable of identifying the request language, then the system generates the response in a language previously configured by default (that should be the region/country primary one).
-
The multi-language feature can be activated or deactivated by ATRIA constructors, as well as configured to meet their requirements and needs.
Technical guidelines
How constructors can configure ATRIA multi-language feature?
Constructors can configure this feature through different parameters of the prompt:
ATRIA server internal configuration
The ATRIA server configuration responsible for managing the multi-language feature includes these fields:
5 - Generative feedback
Generative feedback functional description
Discover the feedback functionality that can be used for Generative AI and RAG capabilities
If you are interested in the detailed technical operational flow of this capability, that includes the sequence diagram of interactions between components, access here
Introduction
Within the use of the ATRIA AI-driven Generative AI or RAG capabilities, we have developed a feedback functionality.
This feedback functionality allows the estimation of the user’s satisfaction regarding the obtained response.
The user can provide feedback by clicking on a thumbs-up icon if the quality and appropriateness of the answer is correct or selecting the thumbs-down icon if the response misses the point, contains hallucinations, or is unclear.
Functional operation
The underlying process is summarized in the following lines and schematically shown in the figure below:
- An application sends a request to aura-gateway-api generative with a correlator.
- Firstly, it passes through Kernel (Telefónica Digital Ecosystem) for authentication and security purposes.
- aura-gateway-api processes the received request and sends the request to the auto-generative content generator atria-model-gateway to obtain an appropriate response.
- atria-model-gateway generates the most appropriate response and sends it back to aura-gateway-api.
- aura-gateway-api sends the response back to the service that initiated the request with the same correlator and a session identifier.
- An application sends a request to aura-gateway-api feedback with:
- A new header correlator
- The
sessionId received in the path
- The field
msg_corrid, in the body, that indicates the correlator of the message the feedback is about.
- aura-gateway-api processes the received request and communicates with atria-model-gateway to send this request.
- atria-model-gateway stores the feedback.
- aura-gateway-api communicates a
204 to the application.