ATRIA technical guidelines
Guidelines detailing specific technical processes for different technical profiles (DevOps, use case builders, NLP experts, linguists, etc.) who want to use ATRIA capabilities or operate our AI-driven platform

Index of ATRIA technical guidelines
- Build e2e experiences
- Publish an API in Kernel
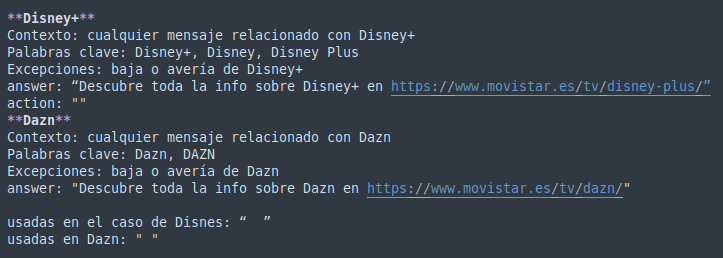
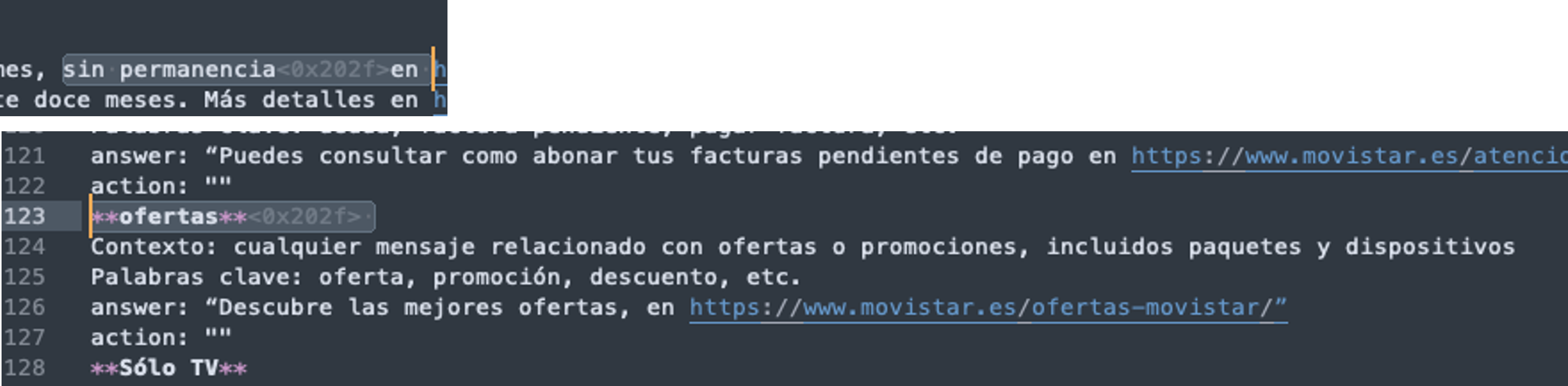
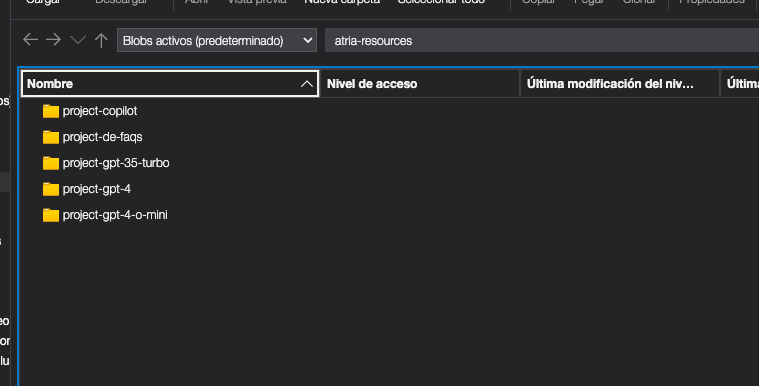
- Configure an application
- Hot swapping of applications
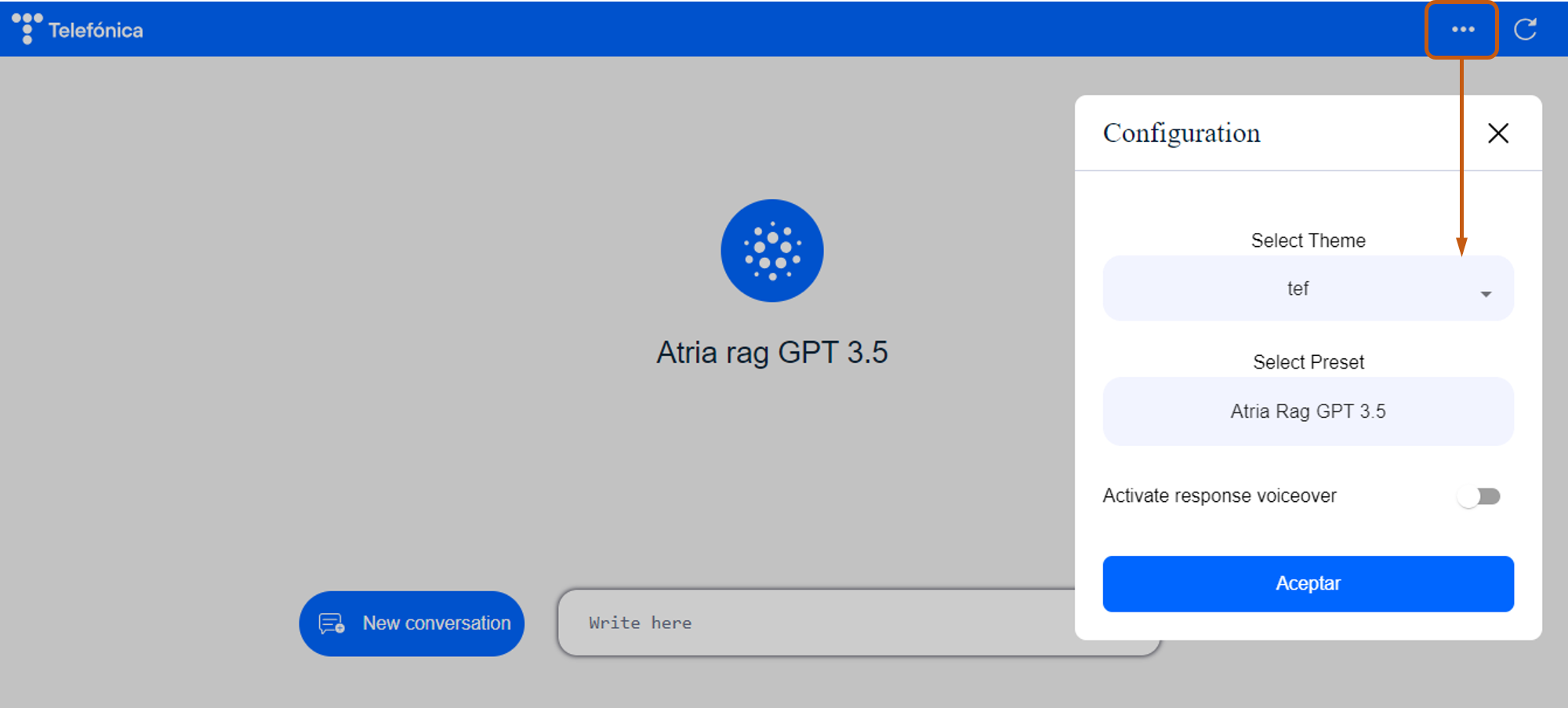
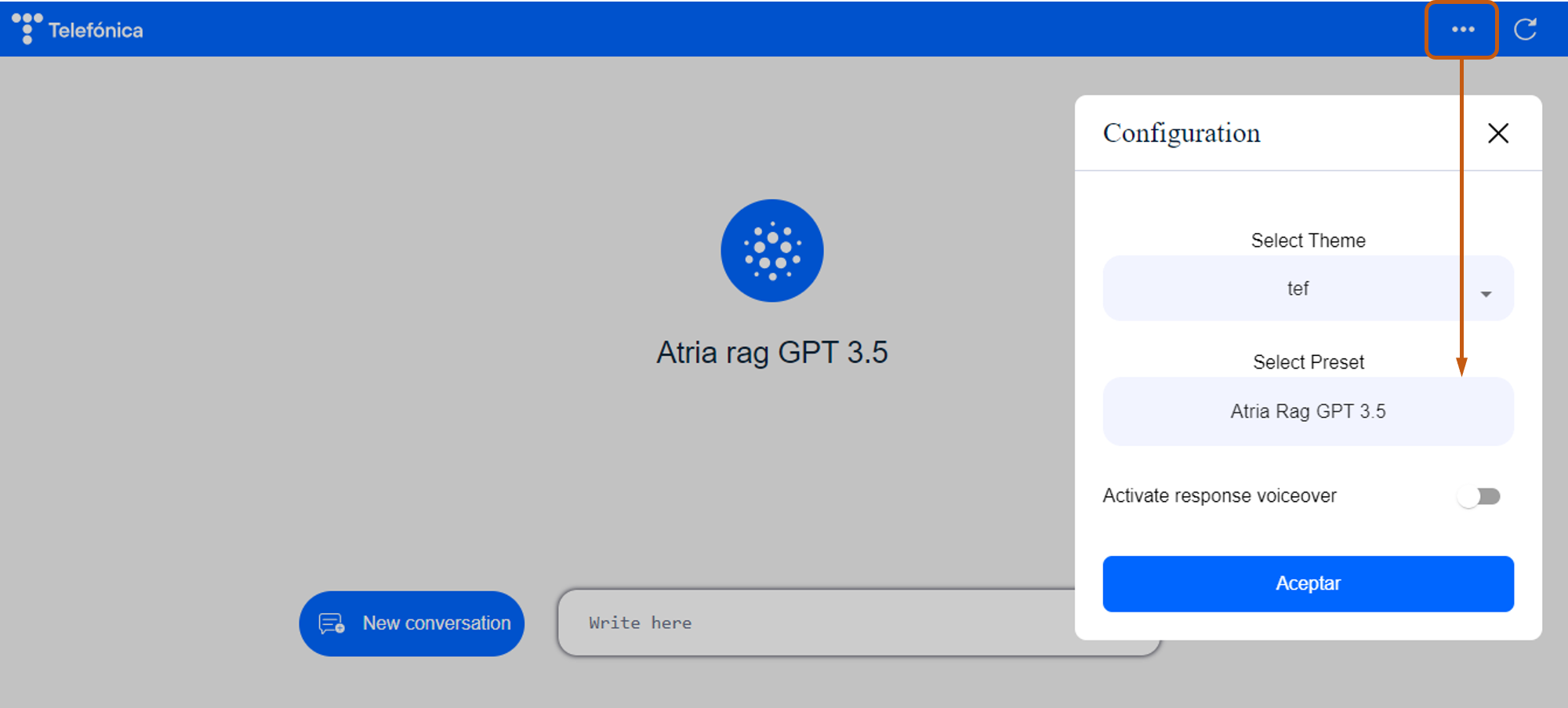
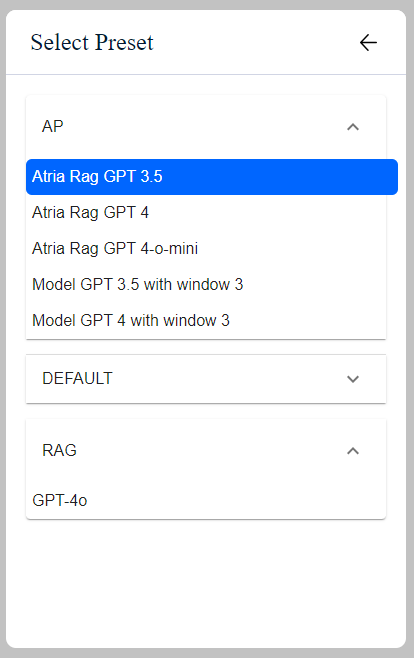
- ATRIA configuration
- Get Kernel access token
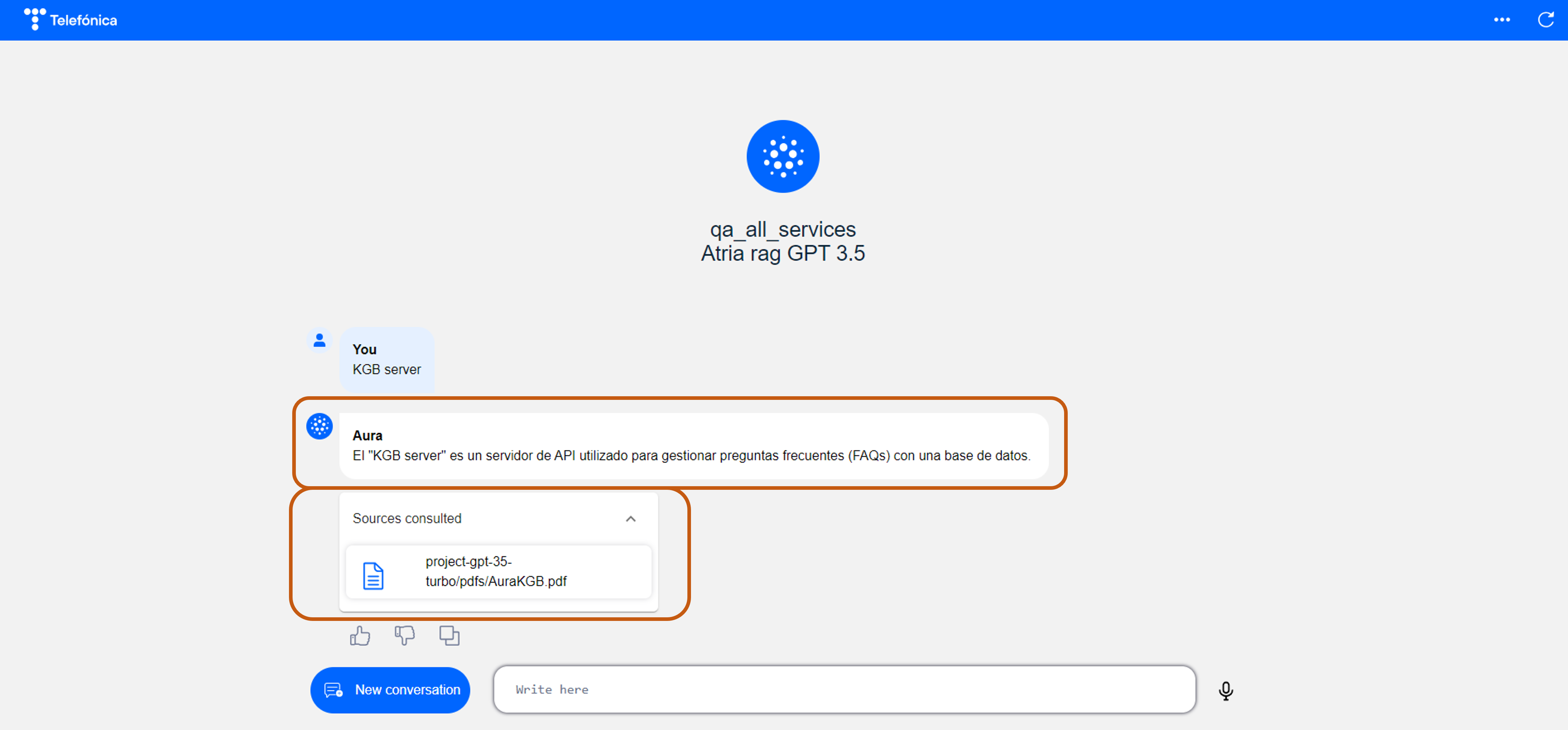
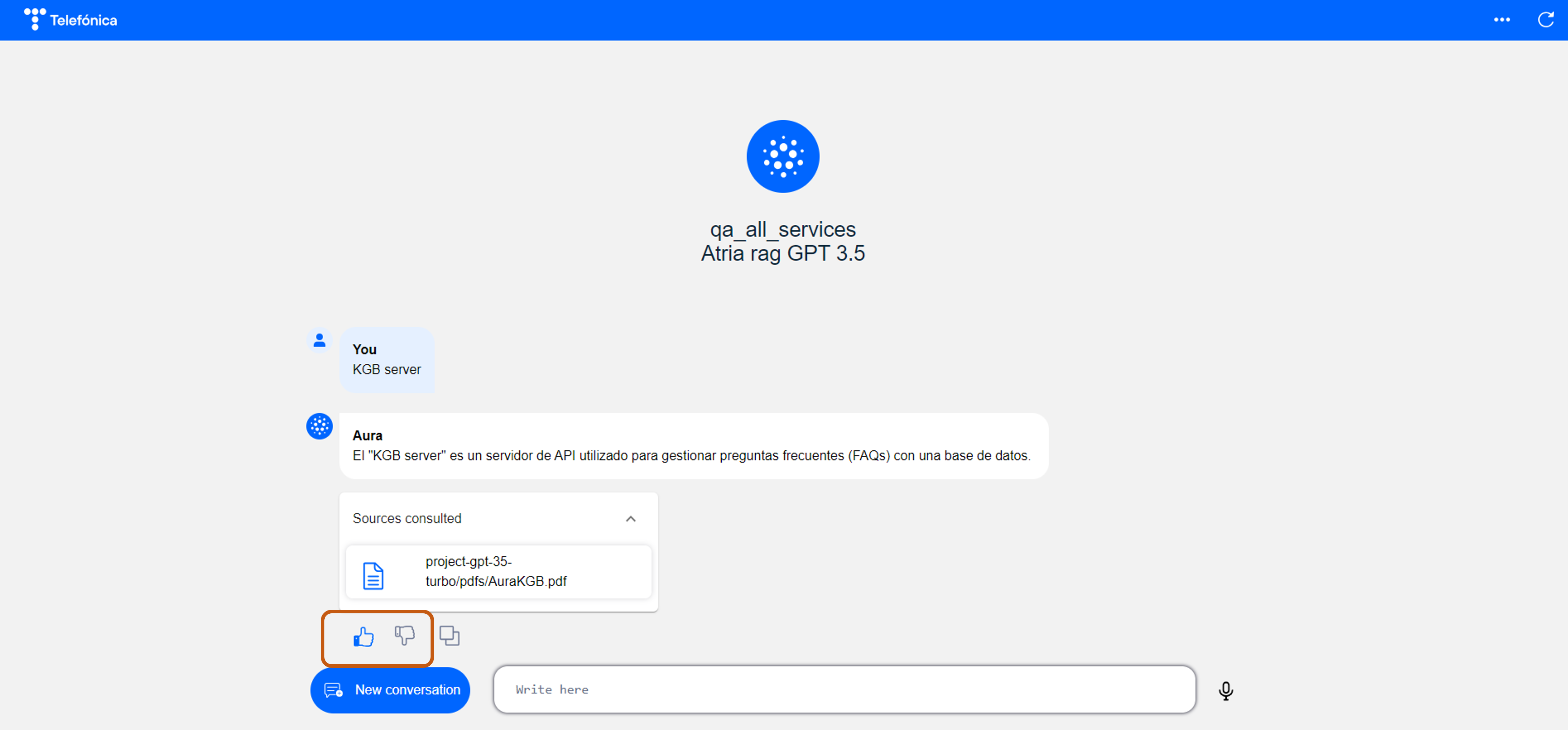
- Request to Aura NLP Resolution API
- Request to Aura Generative API
- Use ATRIA web interface (aura-manager)
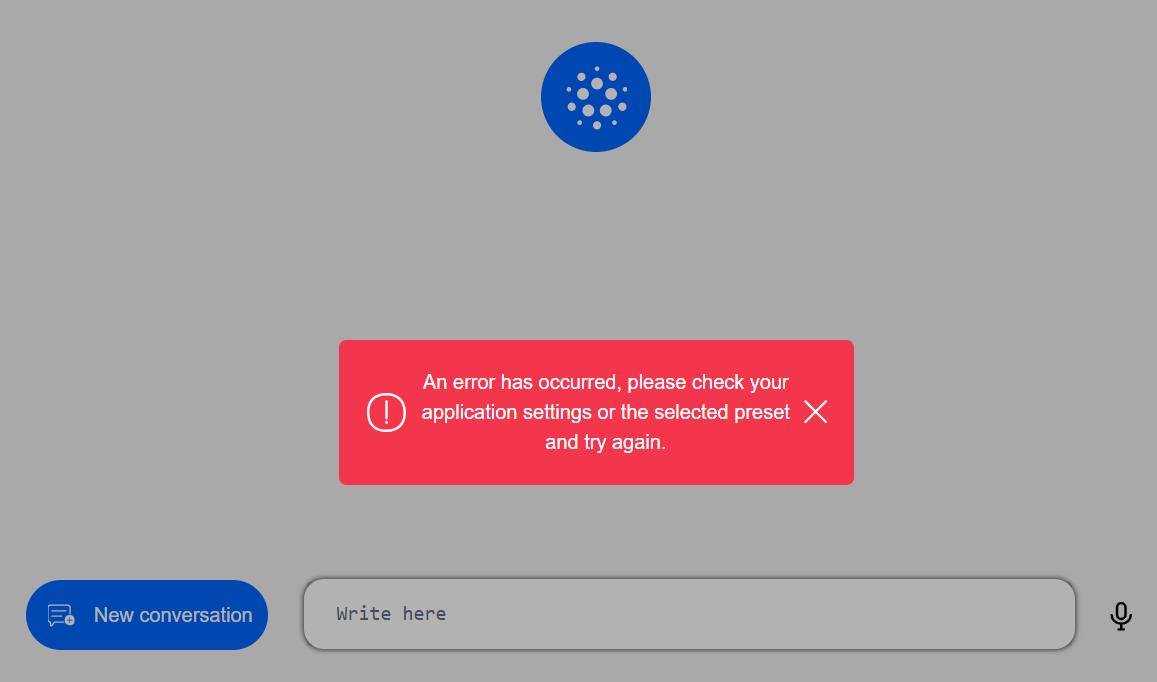
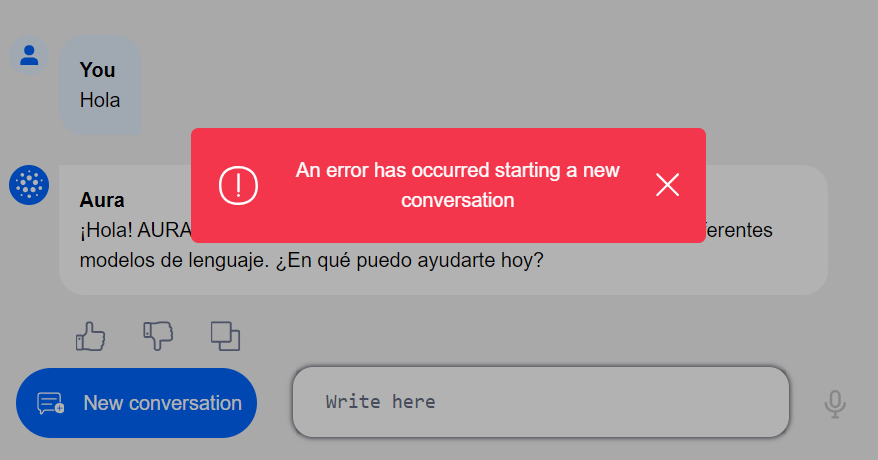
- ATRIA error management
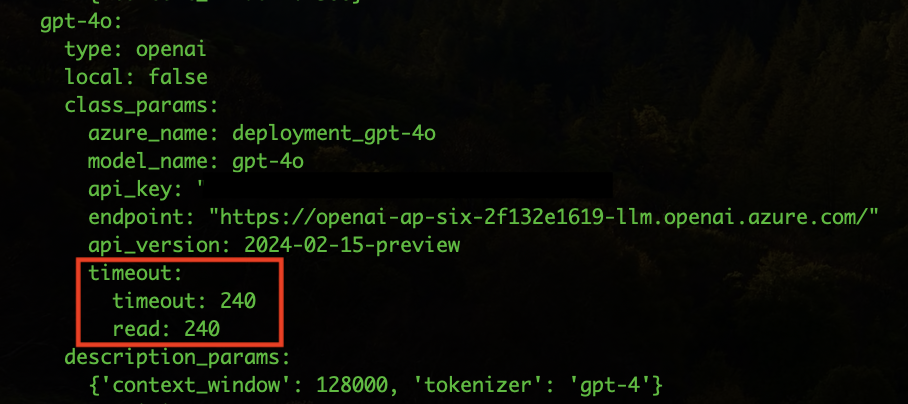
- Adjust timeouts in ATRIA
Other technical guidelines
These guidelines are common to ATRIA and Aura Virtual Assistant
-
Deploy Aura: Deployment Task Center
-
Develop and operate ATRIA: Developers Workspace