This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Aura NLP
Aura NLP
Aura NLP is the component in charge of processing, analyzing and understanding human natural language. Discover throughout these documents key descriptive documentation regarding this component.
Shared component between Aura Virtual Assistant and ATRIA
Related documents
Use cases development over Aura NLP
What is Aura NLP?
Aura NLP (Natural Language Processing) is the module of Aura Cognitive Services in charge of processing and understanding human natural language in simplified use cases.
Aura’s interaction with users is based on the intent & entity model: a user’s request expressed in natural language is understood by Aura in terms of identifying the user’s intent and the associated entities.
An NLP model contains three basic components: stages, connectors and pipelines. Stages provide different methods for the recognition of intents and entities in the user’s utterance. They are linked through different types of connectors composing an NLP pipeline.
When developing a use case, linguists or NLP experts must build up the NLP model and train it, that is, teach Aura to understand. Afterwards, the model is tested through an ongoing and cyclical process until its accuracy is good enough in terms of recognition of the use case intent and entities.
Throughout this section, you can access to detailed information, both descriptive and practical, regarding Aura NLP:
📄 Aura NLP basic concepts and components. Key concepts that must be known by linguists in order to manage Aura NLP.
📄 Configuration of the NLP system. Description of NLP operational configuration (internal) and introduction to the configuration of NLP stages.
📄 API definition
📄 Moreover, access our practical guidelines for NLP experts and linguists: Train Aura to understand: Use cases development over Aura NLP.
Overview of intent and entities recognition
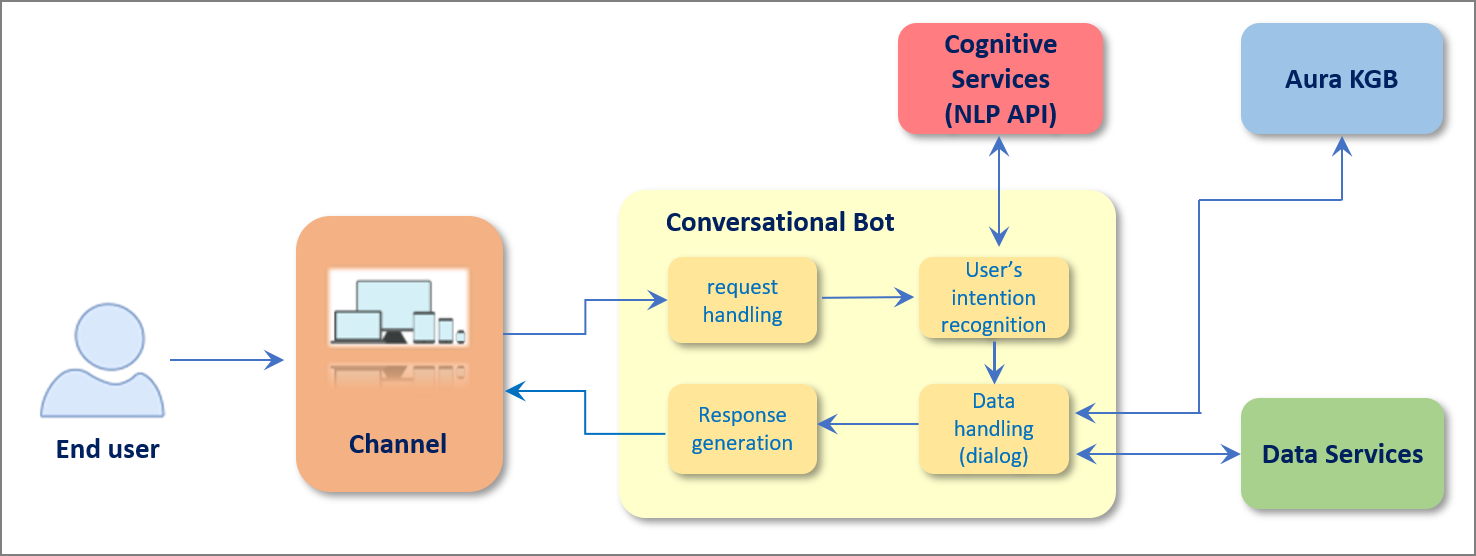
Aura’s conversational process with the user is composed of three overall stages: the user makes a request to Aura; Aura recognizes the user’s intent and associated entities; Aura provides the user with the requested answer or service.
Two are the main actors in the process: while aura-bot is the component in charge of handling the conversational flow with the user, Aura NLP is responsible for the understanding process, which is schematically shown below.
-
Aura user asks for a service/request (utterance) through a specific channel.
-
aura-bot receives the request and handles it. For its understanding, aura-bot summons Aura NLP.
-
Aura NLP recognizes the intents and associated entities in the user request and sends the information back to aura-bot.
1 - Concepts and components
Aura NLP basic concepts and components
Basic concepts related to Aura NLP, components in Aura NLP architecture, catalogs and dictionaries
Utterance
An utterance is any textual input produced by the user that Aura receives through a specific communication channel and needs to understand, interpret and act accordingly.
It may be a whole sentence, a phrase, or a single word. There can be many utterance variations for a particular intent.
Examples of utterances:
- “I want to watch Frozen”; “Play the movie Frozen”; “Frozen”; “Aura, search Frozen”
- “Show my bill”; “I want my bill”; “Bill”; “Hello, check my bill”
Use case
A use case is a written description of a certain functionality in Aura that is launched both by direct request from a user or through the data analysis of the user’s behavior.
A certain use case can be expressed by the user in a large variety of utterances through natural language, therefore Aura is intended to understand all those possible requests.
Examples of use cases:
- TV search
- Check my bill
- Change subtitles to English
Intent
The intent identifies the concrete action requested by the user, among a set of supported services. In other words, it is what the user is asking for and expects Aura to carry out and is usually defined with a verb.
The general format of an intent name in Aura is: intent.[DOMAIN].[INTENT]
In this format, [DOMAIN] is used for the categorization of use cases belonging to the same topic (i.e., for Telco use cases, different domains can be defined such as billing, data usage, etc.).
Example of intents:
- Pay my bill –>
intent.billing.pay
- Make a phone call –>
intent.communications.call
- Turn off the TV –>
intent.tv.off
When developing a use case, linguists must firstly define the intent associated to their use case:
- Check if the intent already exists in Existing_Intents_n_Entities database and, in that case, use it.
- If not existing, define a new one following the format above. At this stage, it is highly recommended that the intent name is reviewed by Aura Platform Team, in order to avoid further inconsistencies.
An example of an intent and certain associated training statements is shown below:
"intent.billing.check": [
"Bill",
"Billing information",
"Can I see my bill?",
"Check my bill",
"How do I access my bill?",
"Invoice details",
"Show me my last invoice"]
Entity
An entity contains detailed information that is relevant in an utterance and provides specific arguments required to run the service (intent).
Depending on the NLP pipeline stages, entities can be expressed in different formats:
- If CLU stage is used to extract entities, the general format for an entity name is:
[entity_value:entity_type]
- If CLU does not extract entities and an external entity extractor stage is used before CLU (Standard NER, Gazetteer NER or Grammars), entities are defined as:
[entity_type]
- In both cases, the general format for the entity_type is
ent.[object]
Example of entities:
- Pay my bill –> bill
- Make a call –> phone call
- Turn off the TV –> TV
When developing a use case, linguists must define the entities associated to their use case:
- Check if the entity already exists and, in that case, use it.
- If not existing, define new ones following the format above. At this stage, it is highly recommended that the entity name is reviewed by Aura Platform Team, in order to avoid further inconsistencies.
A special situation, when the user’s utterance is recognized by means of the Grammar stage and there are different entities of the same type in the utterance, the format for entities is described in Grammars documentation: Recognition of utterances with several entities in Grammars.
Entity types for CLU
Conversational Language Understanding (CLU) uses the following entity types.
They are fully described in Microsoft documentation: CLU entity components and summarized below:
-
learned: Dict field to include entities of learned component type. This is actually not an entity type, but a feature. Therefore, they are uploaded as model_features and, at the same time, as simple entities (using the same name for both). An example of are those words referring to an audiovisual genre, such as movie, series or documentary.
-
list: Dict field to include entities of list component type. Fixed, closed set of related words along with their synonyms.
-
prebuilts: Dict field to include entities of prebuilt component type.
-
regex: Dict field to include entities of regex component type.
-
combination: Field for the combination of components as one entity when they overlap.
Aura NLP basic components: stages, connectors and pipelines
Stages
Aura NLP provides a set of stages that encompasses different methods for natural language processing.
Each stage carries out a specific process to be executed with the user’s utterance with the final goal of recognizing the user’s intent and associated entities.
You can use different stages in an NLP model, both internal stages developed by Aura Cognitive Team or external ones such as Microsoft CLU for intents recognition, NER (Named Entity Recognition) stages for entities recognition, Grammars engine (GrapeNLP & Unitex, that provide a deterministic recognition of intents, etc.
📃 Check the current available NLP stages.
Connectors
Connectors are components that connect different NLP stages and control the flow of the complete pipeline.
Aura NLP integrates several types of connectors, that provide a different behavior to the pipeline: logical connectors, selection connectors and disambiguation connectors.
📃 Check the current available NLP connectors.
NLP pipeline
NLP stages and connectors are integrated into a key component of Aura NLP: the pipeline. An Aura NLP pipeline is a set of wired stages composing a big topology that defines the processing to be performed during the natural language recognition phase.
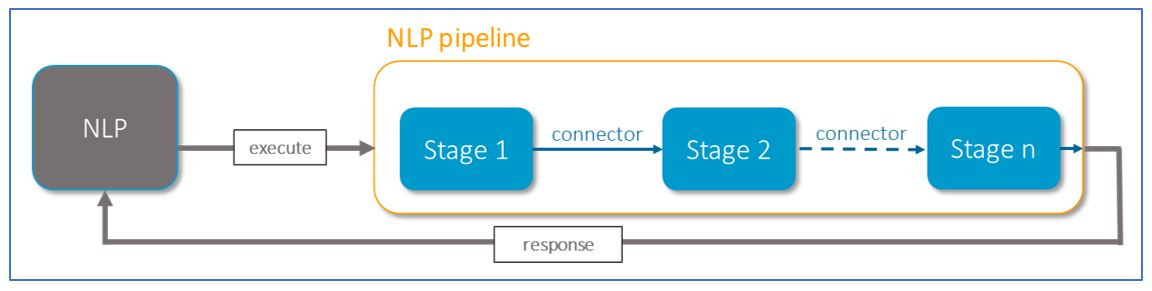
In the current release, Aura NLP includes:
- Normalization pipelines: Pipelines composed of different stages used for the normalization of the user’s utterance.
- Dynamic pipeline: Pipeline designed using different stages and connectors. The pipeline must be defined for each channel and included in a file named
pipeline.json.
Catalogs and dictionaries
NLP dictionaries
The recognition of entities in the Aura NLP model is based on dictionaries: knowledge bases of entities that are included in the NLP model as part of stages for entities recognition.
They are automatically generated from catalogs through the execution of a script.
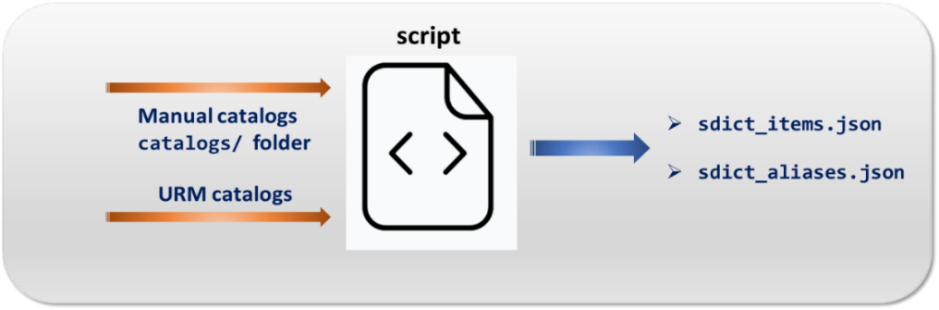
- Access to detailed information regarding what are Aura NLP dictionaries, types and guidelines for the generation or update of dictionaries in generation of Aura NLP dictionaries.
Catalogs
Catalogs are the source for entities to be included in an NLP model. Entities in catalogs are the input for the script that generates the NLP dictionaries.
There are two types of data in catalogs, at least one of them is required: manual catalogs and automatic catalogs that fetch data from Kernel URM database.
- Access to detailed information regarding what are entities catalogs, types and guidelines for the generation or update of catalogs in generation of Aura NLP catalogs.
2 - Internal configuration
NLP system configuration
Internal configuration of Aura NLP system: operational configuration and configuration of NLP stages
Introduction
The configuration of the NLP system is organized in two different purposes, each of them supported by one configuration file:
NLP operational configuration: bootstrap.cfg
The bootstrap.cfg file contains operational config sections for Aura NLP (ports, URIs, usernames, passwords, etc.).
This file can be found in the path:
aura-nlpdata-[country_code]/config/etc/bootstrap.cfg
⚠️ When developing a use case, NLP engineers or linguists should not modify this file. If any modification is required, it must be approved by the Aura Platform Team.
The file follows the general structure shown hereunder:
[working_directory]
stages_folder =./tmp/
[logging]
handlers = { . . . }
loggers = { . . . }
root = { . . . }
[country-langs]
country_mapper = { . . . }
[channels]
channel_list = [
{
'prefix': 'fb',
'name': 'whatsapp',
'id': '269d6-f052-4d2e-8f66-f59a9f31eff9'
},
. . . ]
[platform]
platform = 'ES'
[azure_models]
container_url = ${AZURE_NLP_MODELS_URL}
Moreover, it is required to include in this file other different sections belonging to specific stages or databases used.
The fields included in each section are described below.
Working directory
[working_directory]
stages_folder = ./tmp/
The main fields are explained below:
stages_folder: Main directory for the different stages.
Logging
[logging]
handlers = {
'hdl1': {
'class':'logging.StreamHandler',
'formatter':'console',
'level':'INFO'
}
}
loggers = {
'nlp': {
'level': 'INFO',
'handlers': [
'hdl1'
],
'filters': []
}
}
root = {
'level':'INFO',
'handlers': [
'hdl1'
]
}
The main fields are explained below. However, for more details, developers are kindly requested to read the General Python logging documentation
-
handlers: This field configures a dictionary with different logging handlers. Each key is the name of a handler, and it is composed by the next parameters:
class: It is configured with Python logging handlers (See Python documentation).formatter: It configures the format of logs. It must be filled with the labels json, string, console or simple.level: Level of the logging event. It must be filled with the labels INFO, ERROR, WARN or DEBUG.
-
loggers: The corresponding value is a Python dictionary in which each key is a logger name and each value is a dictionary describing how to configure the corresponding Logger instance:
level (optional parameter): Level of the logger.handlers (optional parameter): List of IDs of the handlers for this logger.filters (optional parameter): List of IDs of the filters for this logger.
-
root: Configuration for the root logger.
level (optional parameter): Level of the logger.handlers (optional parameter): List of IDs of the handlers for this logger.
[country-langs]
country_mapper = {
'es-es': {
'country_name': 'Spain',
'language_name': 'Spanish',
'alpha2': 'es',
'alpha3': 'esp',
'culture': 'es-es'
}
}
[channels]
channel_list = [
{
'prefix': 'mp',
'name': 'movistar-plus',
'id': '60f0ffda-e58a-4a96-aad9-d42be70b7b42'
},
]
[platform]
platform = 'ES'
The main fields are explained below:
-
country_mapper: Mapper with a list of fields that specifies the allowed languages based on the ISO-639 code.
-
channel_list: List of available channels. This field must contain three parameters for each channel. This information is already configured for every OB.
prefix: Prefix of the channel.name: Name of the channel.id: ID of the channel.
-
platform: Allowed platform.
CLU
The CLU stage requires a specific operational configuration:
[CLU]
base_url = https://${RESOURCE_NAME_CLU}.cognitiveservices.azure.com
base_url_api = https://${RESOURCE_NAME_CLU}.cognitiveservices.azure.com
api_version = 2023-04-01
http_retry_codes = {429, 500}
http_max_attempts = 10
http_sleep_time = 5
http_time_out = 60
http_time_out_recognizer = 60
http_retry_codes_recognizer = {429, 500}
http_max_attempts_recognizer = 5
http_sleep_time_recognizer = 0.5
http_raise_when_retry_limit_exceeded_recognizer = True
The main fields are explained below:
base_url: Base URL for CLU service.base_url_api: Base URL for CLU API service.api_version: CLU API version.http_retry_codes: Response status code, if more requests than the limit have been sent.http_max_attemps: Maximum number of HTTP requests allowed.http_sleep_time: Timeout between HTTP requests.http_time_out: Time in seconds for raising a timeout exception when HTTP request does not return a response for
training API requests.http_time_out_recognizer: Time in seconds for raising a timeout exception when HTTP request does not return a
response for CLU recognizer.http_retry_codes_recognizer: Set of response status codes that will retry CLU recognizer request.http_max_attemps_recognizer: Maximum number of attempts that will be performed in CLU recognizer request when there
is an exception by timeout or connection error or a request code defined in http_retry_codes_recognizer is set.http_sleep_time_recognizer: Time to wait between HTTP CLU recognizer requests.http_raise_when_retry_limit_exceeded_recognizer: Boolean (true/false) value to inform if an exception must be
re-raised when it happens and the maximum number of retries is exceeded.
OpenAI Embeddings
The OpenAI Embeddings stage configuration allows to have different databases per each combination of language and channel.
Some of these values will be configured by the installer aurak8s, such as base_url_api.
It is also necessary to enable its configuration in aurak8s installer, following the instructions in the Enable OpenAI deployment section.
[openai_embeddings_recognizer]
azure_token_base_url = https://login.microsoftonline.com
management_url = https://management.azure.com
management_api_version = 2023-05-01
http_retry_codes = {429,500}
http_max_attempts = 10
http_sleep_time = 5
http_time_out = 30
base_url_api = https://test.openai.azure.com/openai
base_api_version = 2023-05-15
http_time_out_recognizer = 20
http_retry_codes_recognizer = {429,500}
http_max_attempts_recognizer = 10
http_sleep_time_recognizer = 10
http_raise_when_retry_limit_exceeded_recognizer = True
sku_name = Standard
sku_capacity = 120
[qdrant:instance]
url = http://hotname:6333
api_key = api-test
shard_number = 1
replication_factor = 1
chunk_size = 30
exponential_sleep = True
max_exponential_sleep_time = 120
The associated fields are defined below:
azure_token_base_url: Base URL to get oauth token.management_url: Azure URL where the embedding OpenAI model will be deployed.management_api_version: Version of the embedding OpenAI model in Azure.http_retry_codes: Response status code to retry request.http_max_attemps: Maximum number of HTTP requests allowed.http_sleep_time: Timeout for each attempt when we retry any HTTP request.http_time_out: Time in seconds for raising a timeout exception when HTTP request does not return a response for OpenAI embeddings training API requests.base_url_api: Base URL for OpenAI embeddings service.base_api_version: OpenAI embeddings version.http_time_out_recognizer: Time in seconds for raising a timeout exception when HTTP request does not return a response for OpenAI embeddings recognizer.http_retry_codes_recognizer: Set of response status codes that will retry OpenAI embeddings recognizer request.http_max_attemps_recognizer: Maximum number of attempts that will be performed in OpenAI embeddings recognizer request when there is an exception by timeout or connection error or a request code defined in http_retry_codes_recognizer.http_sleep_time_recognizer: Time to wait between HTTP OpenAI embeddings recognizer requests.http_raise_when_retry_limit_exceeded_recognizer: Boolean (true/false) value to inform if an exception must be re-raised when it happens and the maximum number of retries is exceeded.sku_name: Name of the resource model representing the SKU.sku_capacity: Capacity of Tokens per Minute Rate Limit (Thousands).url: URL for Qdrant service.api_key: Key needed to connect with Qdrant service.shard_number: Number of shards for Qdrant service.replication_factor: Replication factor for Qdrant service.chunk_size: Number of embeddings to be sent in each request to the Qdrant service.exponential_sleep: Boolean (true/false) value to inform if the exponential sleep is enabled. By default, it is False.max_exponential_sleep_time: Maximum time in seconds for the exponential sleep. By default, it is 120 seconds.
base_url_api = https://internal.com/
http_retry_codes = {429, 500}
http_max_attempts = 10
http_sleep_time = 5
http_time_out = 30
Where:
http_retry_codes: Response status code to retry request.http_max_attempts: Maximum number of HTTP requests allowed.http_sleep_time: Timeout for each attempt when we retry any HTTP request.
Azure models
The azure_models configuration is detailed below:
[azure_models]
container_url = ${AZURE_NLP_MODELS_URL}
Where:
container_url: URL for the Azure NLP models container.
Embeddings Domain Classifier
The Embeddings Domain Classifier stage configuration allows the use of different databases per each combination of language and channel.
Some of these values will be configured by the installer aurak8s, such as base_url_api.
It is also necessary to enable its configuration in aurak8s installer, following the instructions in the Enable OpenAI deployment section.
[openai_embeddings_domain_classifier]
azure_token_base_url = https://login.microsoftonline.com
management_url = https://management.azure.com
management_api_version = 2023-05-01
http_retry_codes = {429,500}
http_max_attempts = 10
http_sleep_time = 5
http_time_out = 30
base_url_api = https://test.openai.azure.com/openai
base_api_version = 2023-05-15
http_time_out_domain_classifier = 20
http_retry_codes_domain_classifier = {429,500}
http_max_attempts_domain_classifier = 10
http_sleep_time_domain_classifier = 10
http_raise_when_retry_limit_exceeded_domain_classifier = True
sku_name = Standard
sku_capacity = 120
[qdrant:instance]
url = http://hotname:6333
api_key = api-test
shard_number = 1
replication_factor = 1
chunk_size = 30
exponential_sleep = True
max_exponential_sleep_time = 120
The associated fields are defined below:
azure_token_base_url: Base URL to get oauth token.management_url: Azure URL where the embedding OpenAI model will be deployed.management_api_version: Version of the embedding OpenAI model in Azure.http_retry_codes: Response status code to retry request.http_max_attemps: Maximum number of HTTP requests allowed.http_sleep_time: Timeout for each attempt when we retry any HTTP request.http_time_out: Time in seconds for raising a timeout exception when HTTP request does not return a response for OpenAI embeddings training API requests.base_url_api: Base URL for OpenAI embeddings service.base_api_version: OpenAI embeddings version.http_time_out_domain_classifier: Time in seconds for raising a timeout exception when HTTP request does not return a response for embeddings domain classifier.http_retry_codes_domain_classifier: Set of response status codes that will retry embeddings domain classifier request.http_max_attempts_domain_classifier: Maximum number of attempts that will be performed in embeddings domain classifier request when there is an exception by timeout or connection error or a request code defined in http_retry_codes_domain_classifier.http_sleep_time_domain_classifier: Time to wait between HTTP embeddings domain classifier requests.http_raise_when_retry_limit_exceeded_domain_classifier: Boolean (true/false) value to inform if an exception must be re-raised when it happens and the maximum number of retries is exceeded.sku_name: Name of the resource model representing the SKU.sku_capacity: Capacity of Tokens per Minute Rate Limit (Thousands).url: URL for Qdrant service.api_key: Key needed to connect with Qdrant service.shard_number: Number of shards for Qdrant service.replication_factor: Replication factor for Qdrant service.chunk_size: Number of embeddings to be sent in each request to the Qdrant service.exponential_sleep: Boolean (true/false) value to inform if the exponential sleep is enabled. By default, it is False.max_exponential_sleep_time: Maximum time in seconds for the exponential sleep. By default, it is 120 seconds.