2 - OB analytics
OB analytics
Description of the OB OB Analytics subsystem that can be managed by OBs.
Introduction
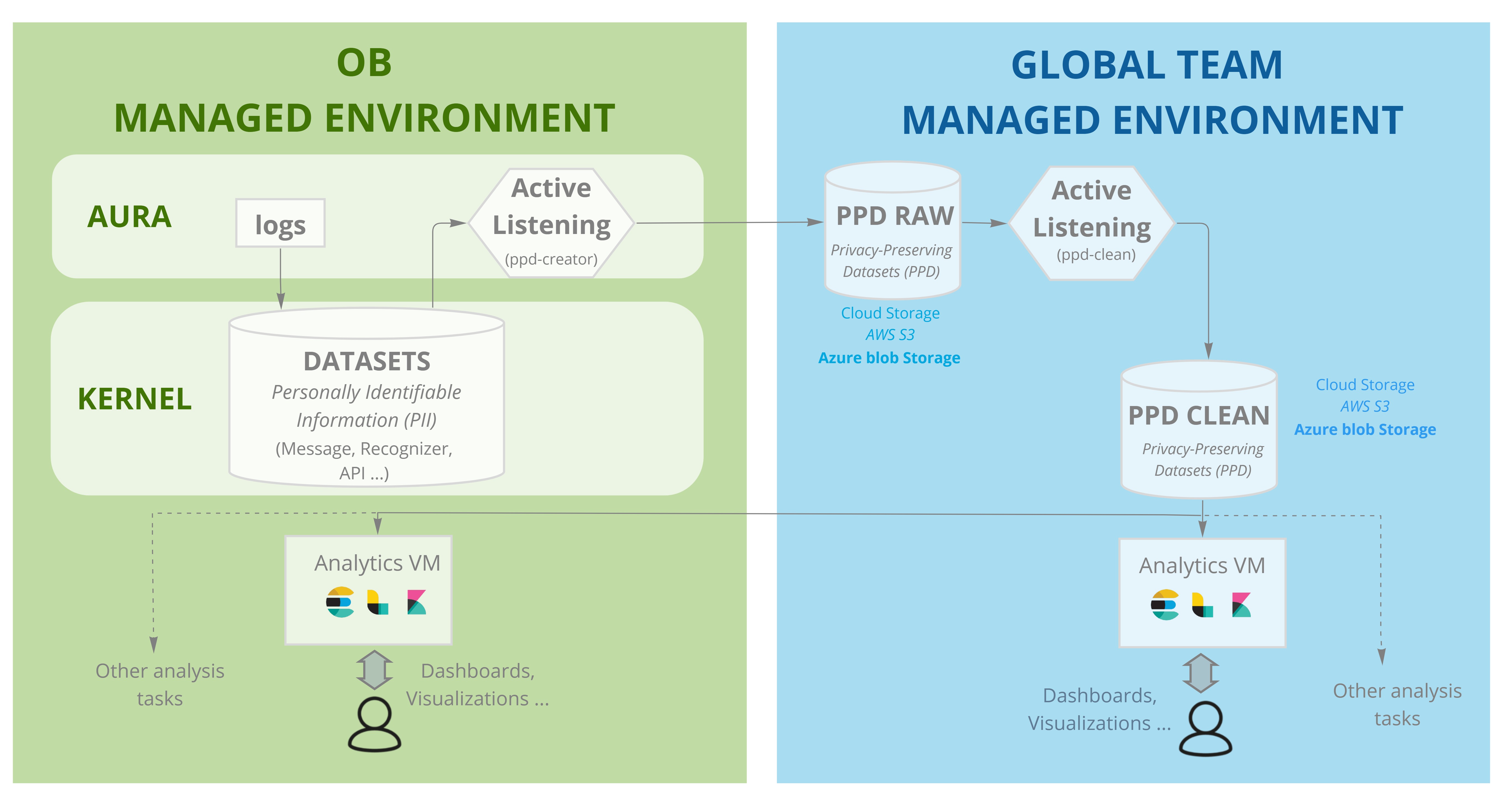
The OB Analytics subsystem is an optional component in the dataflow, which enables the management of clean PPDs (Privacy-Preserving Datasets) by LCDOs for the analysis of Aura behavior.
In order to work with OB Analytics subsystem, the following items must be fulfilled:
-
The legal agreement for log management and creation of PPDs must be signed between the OB and Aura Global Team.
-
The mechanism for PPD creation and transfer must be installed. This requires the deployment of a piece of software (provided by Aura Global Team) inside the OB cloud, with access to the repository (AWS bucket or Azure Blob Storage) holding Aura logs.
-
A virtual machine must be deployed on the OB cloud to hold the OB Dashboard. This virtual server must be provisioned by the OB on the same cloud environment (provider and region, e.g., AWS West Europe) than the Kernel cloud, but separated from it in terms of access rights (placing it in the same cloud enables saving transfer costs from the cloud provider for PPD access).
Architecture and installation
The basic infrastructure of the OB Analytics subsystem consists on a Virtual Machine that is fed with the extracted and cleaned PPDs. This virtual machine is set up with a proposed stack of tools based on the open-source ELK framework (See figure in Architecture document).
-
Elastic Search: indexing database.
-
Logstash: ingester for PPD data, configured to upload the anonymized clean PPD tables into Elastic Search.
-
Kibana: visualization tool offering dashboards and panels created over Elastic Search data.
The OB is required to set up the base VM, for which an Ubuntu 18.04 system is advised.
On top of this base system, Aura Global Team provides an installation kit that includes:
- The pre-processing and ingesting configuration for feeding clean PPD data into logstash.
- The indexing configuration for Elastic Search.
- Certain prototype dashboards and panels for Kibana.
- Basic security provisions (providing web-based secure access to the dashboard).
Once installed, the system automatically ingests any new clean PPD being produced, so that the index and dashboards remain up to date.
In principle, the PPD creation process specifies daily production, since Aura logs are sent to Kernel once a day. This means that information about Aura behavior and user actions on one given day will be available in the dashboards on the following day.
The provided system and installed dashboards are only visualization examples for clean PPDs. The system allows the creation of additional panels that may provide complementary insights on clean PPD elements and OBs are encouraged to explore data as they see fit.
Dashboards can be exported and reimported in a different system, so in addition to the LCDO team adding new analysis features, it is possible to provide later updates to the OB Analytics system. These updates can be provided by the Aura Global Team or shared between OBs.
Outside the dashboard stack, it is also possible to process clean PPD with alternative tools (PPDs are essentially CSV files with a defined structure, so they can be processed with a variety of tools).
Kibana dataflow
The Aura Analytics dashboard follows a standard ELK deployment:
-
An Elastic Search index has been created. It is called aura-message-COUNTRY, and its index schema contains a cleaned version of the AURA MESSAGE table (which registers input and output messages). For details on the fields that this index contains, go to the document Data model.
-
A Logstash configuration ingests into this index the cleaned sets of datapoints that are produced daily as a result of the transfer and processing of Aura logs. This is usually done in the early morning (which will then upload data for the previous day).
-
A Kibana index pattern has been created, matching the uploaded Elastic Search index.
An Elastic Search index is how the data is stored inside the DB; a Kibana index pattern is how it is visualized in the interface. Typically, Kibana index patterns match Elastic Search indices, but it is, for example, possible to create a Kibana index pattern that matches more than one Elastic Search index and hence combines different data sources.
-
A small set of visualizations have been pre-installed in Kibana over that index pattern, as a means to get a default peek on the index data. See the section preinstalled visual elements to check them.
This configuration is deployed on the Kibana default space (the only one available on a freshly created Aura Analytics dashboard). If there is the need to create additional spaces, to better organize visualizations, then the Elastic Search index pattern needs to be installed into those additional spaces.
Preinstalled visual elements
Kibana offers many possibilities to visualize the ingested data and there are many resources and tutorials around explaining its mechanics. We therefore refer to the official Kibana documentation, or tutorials available on the web, for generic information.
In the particular case of the Aura Analytics deployment, there is an Elastic Search index that gets automatically ingested daily. It is called Aura-message-COUNTRY and contains a cleaned version of the AURA MESSAGE table (which registers input and output messages).
Over this index, three types of panels/visualizations have been preinstalled, to provide a starting point:
- Discover panel
- Visualizations
- Dashboards
These preinstalled elements are described in the following subsections. To access them, select the appropriate icon in the left navigation panel.
Discover panel
The Discover panel in Kibana is an essential tool where one can perform queries to an Elastic Search index (and save those searches if desired), and explore users’ interactions with Aura in detail log by log, these being filtered by:
- Search terms or conditions
- A time interval
- Additional filters applied to the query results
- A set of index fields to show in the result table
These 4 steps are represented in the following figure:
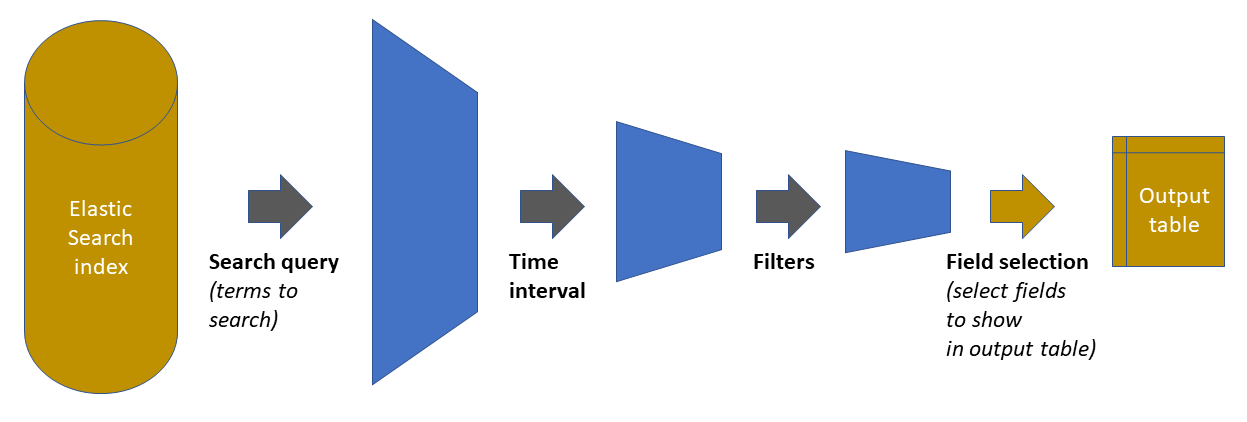
As shown in the previous figure, the starting point is the Elastic Search index holding all the data. The three first steps in the chain reduces the amount of data handled, by pruning out elements that do not satisfy the defined condition. The fourth step is just a display adjustment: on the final dataset, define which of the available fields will be shown on the output table that appears in the panel. However, the retrieved data contains all fields (clicking on any of the rows will show them).
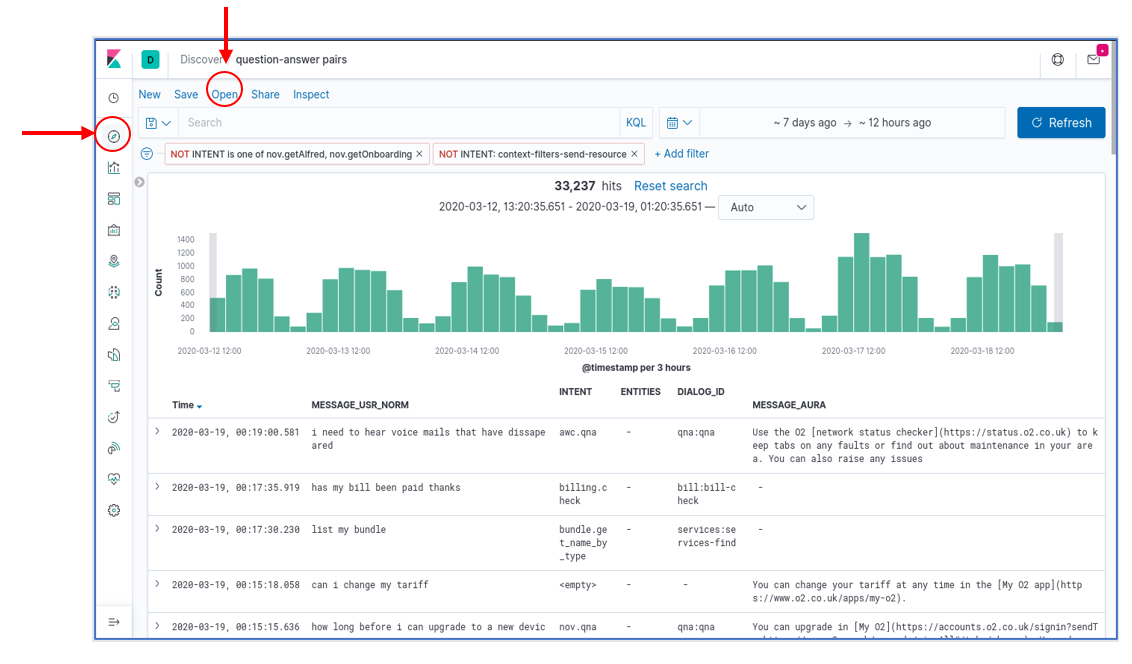
In the Aura Dashboard default set, there is one Discover panel preinstalled. It is called question-answer pairs and has the following characteristics:
- A blank query (i.e., provide all the results)
- A time interval for the last 7 days
- A “only user” filter: it filters out all intents that correspond to non-user queries (suggestions, help commands from the client application, etc.)
- A visualization that includes: the timestamp, the (cleaned) user message, the detected aura intent, associated entities (if applicable), the dialog that was invoked and Aura’s response
This figure shows a snapshot of this panel. To load it, select the Discover tool in the left navigation bar and then click on the “Open” menu option in the top menu bar. A list of saved panels will be shown, together with the already mentioned “question-answer pairs”.
Once the panel is loaded, each one of the aforementioned four elements can be freely modified. For example, the interface allows:
- Adding new filters with the “+Add Filters” button
- Deactivating the current filters by pressing over the predefined filter and clicking over the “Temporarily Disable” option
- Modifying the query interval with the “calendar” button or “Dates Box”
- Adding a specific query on a given index field(s) by using the “Search Box”, instead of the (default) blank query.
Discover panels can be saved as named objects, to be later loaded at will. So, if needed, any panel (a modified panel or a newly created one) can be saved with a new name to have it available for later loading.
Visualizations
A total of 7 visualizations come preinstalled with the base Aura Dashboard. The list can be obtained from the “visualizations” item in the left menu bar, as shown in the figure, and they are:
- Three “Stats” type visualizations, which provide general statistics on platform usage.
- Four “User” type visualizations, which provide insights on user behavior.
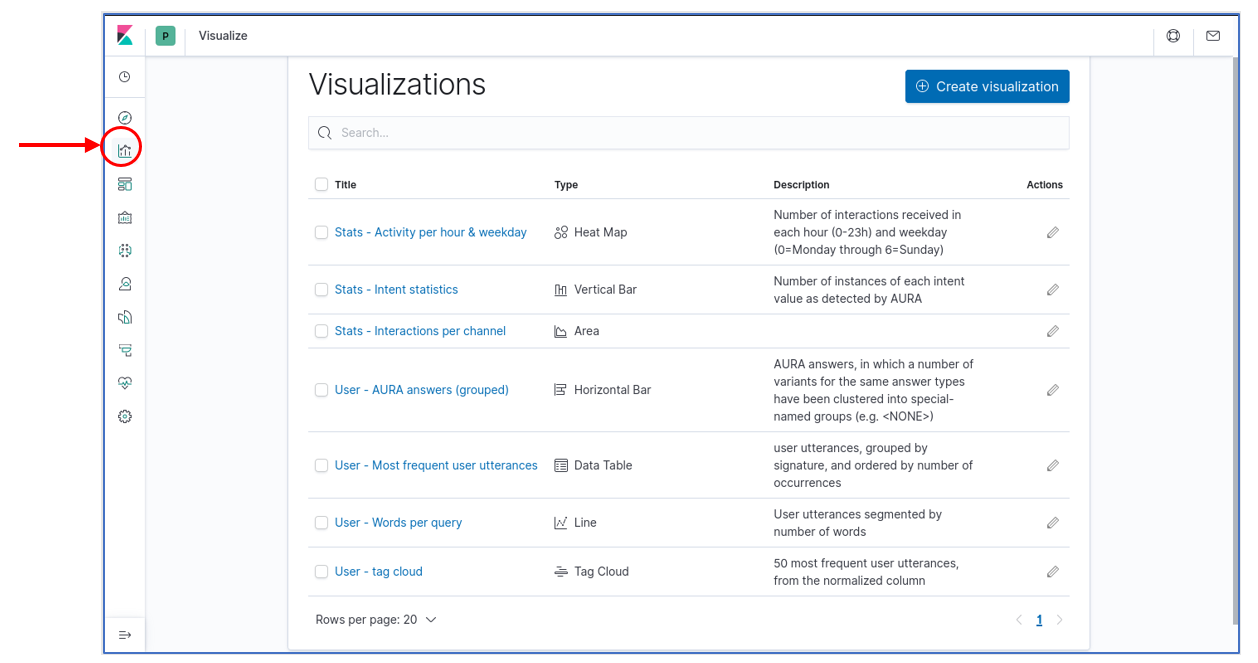
Note that this distinction between “User” and “Stats” is purely conceptual and based on the fields that have been used to generate the visualizations that, from the point of view of Kibana, are all regular visualizations. Those visualizations can be instantly loaded by clicking on their names. But they can also be integrated into dashboards, as described in the next section.
Dashboards
A dashboard in Kibana is essentially a spatial arrangement of visualizations. For example, to construct a dashboard, just place visualizations into a page, resizing them as required, so they can be observed in a single place.
It is interesting to know that in a dashboard all visualizations are linked. So that if, for example, time interval is changed, or a filter is added using the interface, these modifications affect all visualizations in the dashboard and all of them get updated.
Elements in the dashboard visualizations can also generate instant filters by clicking on graphs or table elements. Those filters are then added to the top of the page as a filter and, therefore, can then be modified or removed.
The Aura Analytics default installation preloads two dashboards. Those are available for selection when we click on the “dashboard” icon in the left navigation bar:
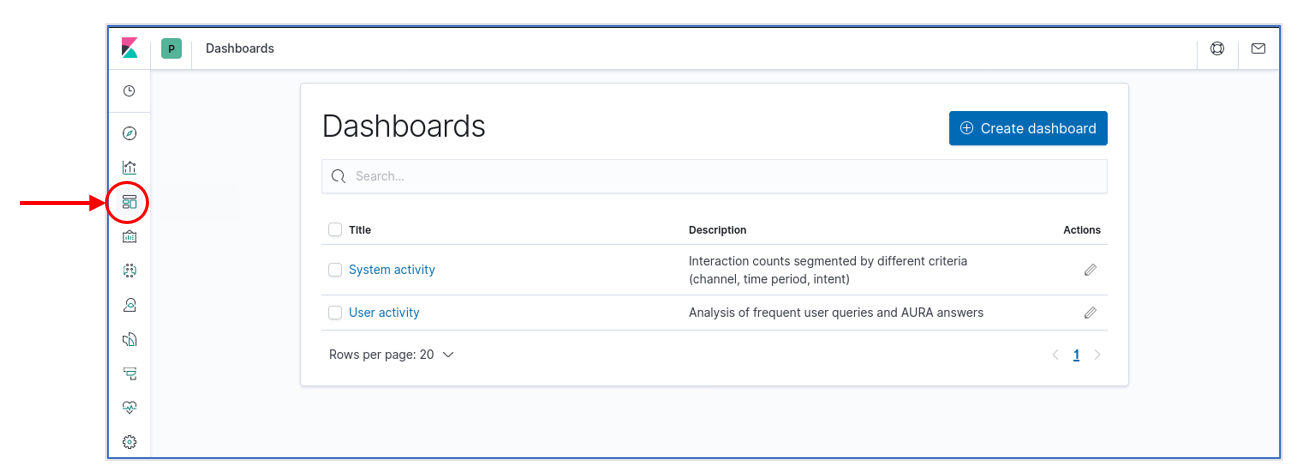
There are different types of dashboards, described in the following sections.
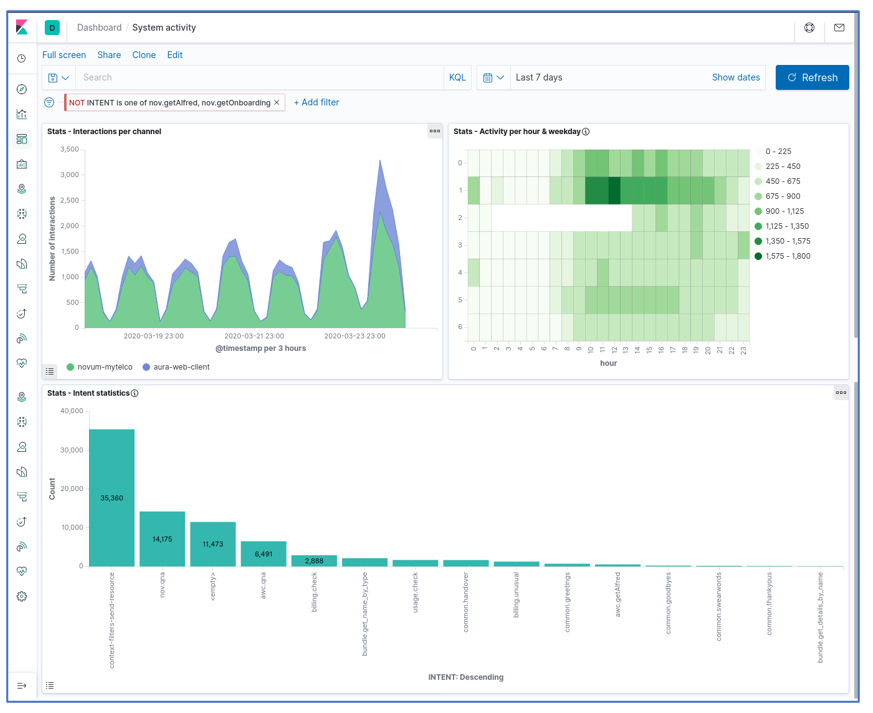
System dashboard
This dashboard integrates the three predefined “Stats” visualizations (generic statistics):
- A timeline of interactions (user messages sent and answered), segmented by channel
- A heatmap of interactions by weekday and time of day (hour)
- A bar graph classifying the interactions produced in the period by detected intent
The following figure shows a screenshot of this dashboard:
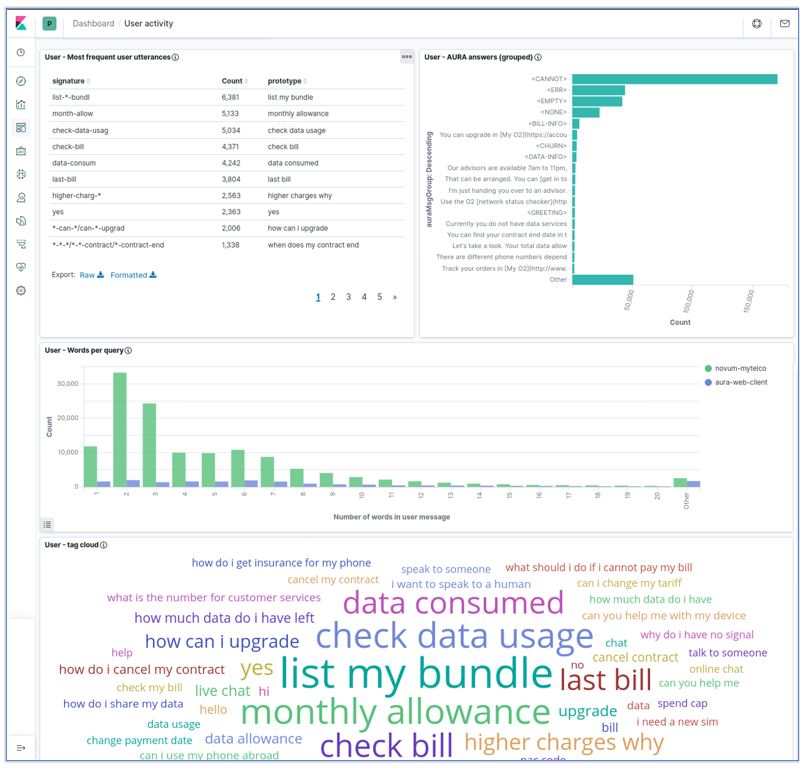
User dashboard
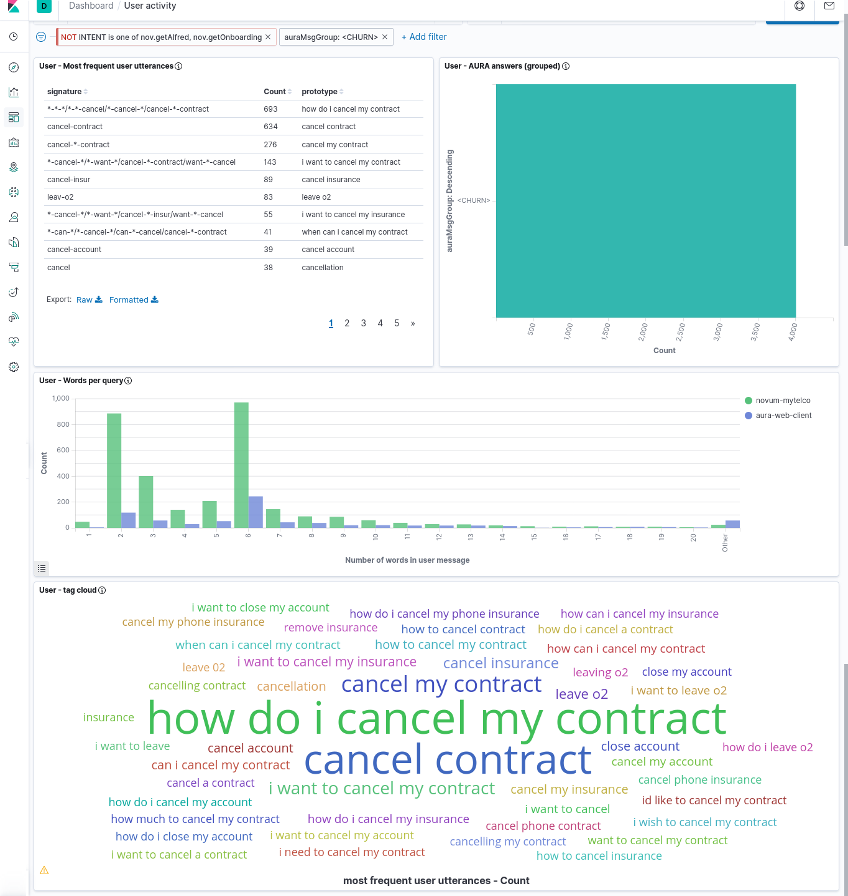
The user dashboard contains the four visualizations:
- Most Frequent User Utterances: list of the most frequent user’s sentences (in the time interval and filter active at the moment). It uses the
usrMsgSig field to group together very similar utterances.
- Aura Answer Groups: list of the most frequent answers that Aura generates, grouped by the semantic categories in
AuraMsgGroup field.
- Words per query: distribution of sizes for the user messages, measured as number of words in the utterance and segmented by channel.
- Tag cloud: set of most frequent user utterances, as a tag cloud in which the font size represents the utterance frequency. The
MESSAGE_USR_NORM field is used for its representation, so it contains normalized utterances.
The next screenshots show the dashboard with all these visualizations (it is a large dashboard, so typically it needs scrolling to visualize all its components).
Note that those four visualizations are linked as they correspond to the same subset of the data (as given by filters and time interval) but they are NOT linked at the individual item level (i.e., a given most frequent user utterance in the left table does not correspond to any specific Aura answer in the right bar graph).
Instead, the dashboard can be manipulated by selecting one specific item in any of the visualization and this will create a filter for the others. For instance, as the following image shows, if we select <CHURN> in the Aura answer group visualization, we can see in the others the user utterances that led Aura to generate that answer (i.e., an answer about contract cancelation).
3 - Data model
Aura Analytics data model
Data model of Aura Analytics 1.1. that can be used as the base for building new elements
Introduction
New elements can be built (or the current elements modified) by making use of the available fields in Kibana through the ingested Elastic Search index.
In this document, we provide a reference of the schema that the index follows, so that it can be used to build such new visualizations, or to better understand the existing ones.
Elements in the Aura-message data model have 3 different types:
-
Numeric: single numbers, integer or real. Suitable for numerical statistics, such as averages, or for plotting variation across time in graphs.
-
Keyword: they are opaque strings, i.e., terms that cannot be searched within (it is not possible to look for words inside a keyword field). They can, however, be used to create some term-level queries, such as prefix queries (find all instances that begin with) and they usually work great for aggregations, since most of them are categorical variables (fields that only have a limited number of possible values) and can therefore be bucketed and counted.
-
Text: these fields are divided into separate terms (words), and some pre-processing is done to them before indexing to improve access though an Elastic Search analyzer. Text fields cannot be used in aggregated visualizations, since they cannot be grouped. They are most useful for queries, because they allow searching for fragments (only a few words) and fuzzy searches.
Fields list
The following table lists all the fields available in the Aura-message-COUNTRY Elastic Search index, together with their type and a brief description.
The most relevant ones include a more detailed description in the section fields explanations.
Note that some fields of text type have a mirror field of type keyword, with the same content. Having the same data indexed in two different ways at the same time (as text and as keyword) enables to perform different types of analysis by choosing the right field.
The “Raw” column indicates if this field is already present in the Aura raw PPD files:
-
Yes: field contained in raw PPDs.
-
No: generated field, produced when creating clean PPDs. They can be recognized as lowercase fields.
-
Partial: It exists in the raw PPDs, but in a somehow different shape.
| Field |
Type |
Raw |
Contents |
| CORR_ID |
keyword |
yes |
Unique identifier for each interaction |
| VERSION_ID |
keyword |
yes |
Aura Platform version |
| CHANNEL_CD |
keyword |
yes |
Identifier for the channel this interaction corresponds to |
| STATUS_CD |
keyword |
yes |
Internal code related to operation status |
| AURA_ID_GLOBAL |
keyword |
yes |
(Mostly) unique identifier for the user |
| AURA_ID |
keyword |
yes |
(Mostly) local identifier for the user |
| INTENT |
keyword |
yes |
Detected user intent, including “system” intents |
| MESSAGE_USR |
text |
partial |
Text request sent by the user |
| MESSAGE_USR_NORM |
text |
no |
A normalized version of MESSAGE_USR |
| MESSAGE_USR_NORM.keyword |
keyword |
no |
A keyword version of MESSAGE_USR_NORM, to enable aggregating on it |
| MESSAGE_AURA |
text |
partial |
Text message sent by AURA to the user |
| MESSAGE_AURA.keyword |
|
partial |
Keyword version of MESSAGE_AURA, to enable aggregating on it |
| MODALITY_CD_USR |
text |
partial |
Modality of the user message |
| MODALITY_CD_AURA |
text |
partial |
Modality of Aura response |
| ENTITIES |
text |
yes |
Comma-separated list of the entities recognized in the user message |
| DIALOG_ID |
text |
yes |
Identifier for the dialog that produced Aura response |
| DIALOG_ID.keyword |
keyword |
yes |
Keyword version of DIALOG_ID, to enable aggregating on it |
| DURATION_NU |
number |
yes |
Elapsed time, in ms, between the reception of the user message and the moment the response is generated to be sent to the channel |
| userType |
keyword |
no |
A single char identifier that characterizes the user as a test user |
| usrMsgWc |
number |
no |
Message word count: number of words contained in the user message |
| usrMsgSig |
keyword |
no |
Message signature: a string that helps clustering user messages |
| AuraMsgGroup |
keyword |
no |
Cluster the Aura response belongs to |
| weekday |
number |
no |
Day of the week the interaction happened (0=Monday to 6=Sunday) |
| hour |
number |
no |
(Integer) hour the interaction happened |
| country |
keyword |
partial |
Two-letter code for the country |
| sesId |
keyword |
no |
Session information |
| sesSize |
number |
no |
Session information |
| sesDuration |
number |
no |
Session information |
Fields explanations
This subsection contains more detailed descriptions of some of the key fields in the schema.
AURA_ID_GLOBAL
This element (mostly) uniquely identifies the user generating the interaction.
Note the concrete value of this field is not the same as the actual identifier used within Aura and uploaded to Kernel: for privacy reasons, the identifier was hashed when generating the PPD and has no resemblance to the original one. The correspondence is however maintained across time, so it is possible to analyse user behavior.
The “mostly” qualifier reflects one quirk of the original Aura identifier: it is generated with a dependence to the authentication method used by the channel, so if two channels follow different authentication methods (e.g., MobileConnect vs. User/Password) then the AURA_ID_GLOBAL identifier for the same user will be different. In summary:
-
The identifier stays the same for a given user across time.
-
Different users will not have the same identifier.
-
But the same user could produce two different identifiers if connected to two channels that use a different authentication method.
AURA_ID
This is a “local” identifier, i.e., one that is generated inside the channel according to specific channel characteristics and it is not tied as much as AURA_ID_GLOBAL to user authentication.
Its main disadvantage is its transient nature: the same user, on the same channel, could generate different AURA_ID strings when connecting different times on a different session. Therefore, for user accounting and tracing, AURA_ID_GLOBAL is usually preferred.
However, there are instances in which AURA_ID works better, namely for anonymous access (when the user is not authenticated). This depends on the channel:
- In the WhatsApp channel, the initial use of the channel will be anonymous from the Aura side (i.e., no authentication is done), hence
AURA_ID_GLOBAL will also be empty (at least until the user authenticates, which depends on the use case). But in this channel, AURA_ID has a permanent value, linked to the WhatsApp user, so here it is a good substitute for a persistent id, even for unauthenticated users.
MESSAGE_USR
This field includes the message sent by the user.
It has been partially processed to enhance anonymization by removing some standard identifiers contained in it with <idxxx> strings (e.g., phone numbers appear as <idphone>).
Removal is done mostly through regular expressions, so there might be occasional glitches (such as identifying as phone a number that does not really correspond to a phone, just because it follows the phone number pattern).
MESSAGE_USR is a field of text type. As such, it is searchable: it is possible to search for specific words the user might have said.
Furthermore, it has been processed through an ElasticSearch analyzer adapted to the specific language used. This means that searches are able to match related words (e.g., plural versions of a singular query word, or verb conjugations). Phrase searches are also possible (by using double quotes around the phrase). If a phrase (several words) is used as a query without the quotes, ElasticSearch interprets it as a query for any of the words, so it will return all data elements that contain any of the words in the query.
In Kibana, more sophisticated text searches can be made by switching Lucene query syntax: proximity queries (words close to each other), fuzzy searches (query words allowing typos), wildcards, etc.
MESSAGE_USR_NORM
This is a normalized version of MESSAGE_USR, in which the user text has been streamlined by:
- Converting all the sentence to lowercase
- Removing all punctuation
- Removing any extra spaces
Furthermore, this field is not processed through a language-dependent analyzer as MESSAGE_USR is, so queries on this field must match words exactly. It is still a text type field. However, the same query language can be used.
MESSAGE_AURA
This contains the text message generated by Aura and sent to the user as response to the user query. It is a text type field, so it is possible to search for specific words in it.
In the current version of Aura KPIs logs, this field only contains the text response. Some Aura use cases do not generate a purely textual message, but a more elaborated one (e.g., a card with text and graphics). These complex answers are inserted as attachments into Aura’s response to the channel and since attachments are not logged into the MESSAGE field, this field will appear empty in those cases. So, an empty MESSAGE_AURA field does not necessarily mean that Aura did not provide an answer. As an alternative for those situations, looking at the DIALOG_ID field (or INTENT) may give a hint of the type of answer that Aura delivered.
MODALITY_CD_USR
This field contains the modality in which the user sent the message.
It is a slightly transformed field because there are some variations across Aura versions and, in order to unify it, the modalities are consolidated into only four different keywords: audio (spoken message), text (written free-text message) o form (commands sent via automatic processing or menus).
DIALOG_ID
This field contains the identifier for the user case dialog module at the aura-bot Framework that was selected to construct the Aura response.
Dialog identifiers have two components (library and dialog) separated by a colon e.g., services:service-usage
This field uses a custom analyser that splits the identifier at the colon, generating two terms. This makes possible to construct queries with one of the terms, e.g., “give me all the elements for the domain services”. But being a text field makes it impossible to do aggregations on it, so it cannot be used for statistics like bar charts (use DIALOG_ID.keyword for that).
DURATION_NU
This number reflects the time that took Aura to understand, process and respond to the user message. It is the difference (in milliseconds) between the timestamp of the moment the user message was received and the timestamp in which Aura’s response was finalized and sent to the channel.
Note that it is not a complete end-to-end delay time from the user’s point of view, since it does not include either the time it took the request to arrive to Aura through the channel or the time it took the response to travel back through the channel and get rendered at the client application (those times are outside Aura, and as such not registered by it).
Session information includes the fields: sesId, sesSize, sesDuration.
These fields are generated by running a process over the time series formed by interactions from each user at each channel.
A session is automatically identified as a consecutive list of such user’s interactions, each separated from the next by a time interval shorter than 5 minutes. Once each session is identified, it is tabulated and labelled with three fields:
-
sesId: string, forming a unique identifier for the session. It should be considered as an opaque identifier and the guarantee is that no other session in the data stream carries the same identifier.
As an aside, interactions that do not correspond to actual user interactions (because no user could be identified or because the datapoint corresponds to an interaction not triggered by the user) are all labelled with a <void> sesId.
-
sesSize: number of interactions this session contains. This is labelled only for the first interaction in the session, all other interactions carry a 0 in this field. Non-sessions such as the ones with <void> sesId will be left empty. This facilitates computing averages or other statistics on valid sessions, by just first filtering out all zero and empty values.
-
sesDuration: time duration for each session, counted from the instant the first user message was received, to the instant the last Aura message was sent. For single-interaction sessions its value will be the same as DURATION_NU, for multiple interactions it will contain the time interval between all of them.
As with sesSize, only the first interaction in a session is annotated with sesDuration; the remaining interactions will be assigned a 0 value (and interactions that do not correspond to a session will be left empty). Therefore, to compute statistics on sesDuration, remove the 0 and empty values first.
userType
This field may be used, in certain cases, to help identify rows that do not correspond to real users but to test users (internal users that belong to test/QA teams and whose behaviour is, therefore, not representative of actual Aura users).
The field contains a single character, which is s for standard (real) users, and can be Q or T for QA/Test users respectively (there are also lowercased versions q and t, referring to unconfirmed test users).
Note that test user identification is not available on every country, since it depends on having a register of the AURA_GLOBAL_ID identifiers that QA/Test users authenticate and this is not always available.
usrMsgSig
This field is not useful by itself. Instead, it is intended to be used to help grouping together very similar user utterances. It does so by generating a signature of the utterance that is (hopefully) insensitive to small variations in the sentence.
This is an experimental field; it might change if we reach a variant that is better suited for its purpose.
The way to generate this signature is by following these steps with the utterance:
-
Start with the normalized utterance (i.e., MESSAGE_USR_NORM).
-
Perform stemming (removal of word suffixes) on all the words. This makes bills and bill the same word.
-
Substitute words from a fixed list of very common, uninformative tokens (stopwords) by an asterisk. For example, this converts both “get my bill” and “get the bill” to the same phrase “get * bill”.
-
Group words in sets of 3 elements (trigrams) and sort them alphabetically. This removes the global structure of the sentence, while retaining local structure.
The resulting string is a non-understandable version of the original utterance (hence, it cannot be used by itself), but the fact that several very similar utterances produce the same signature helps cluster those utterances. An example is one of the preinstalled visualizations “Most Frequent User Utterances” which uses this field to group very similar utterances.
Another example is provided in the following figure, which shows message utterances generating the same signature:

As it can be seen, the signature is the same for “how can I upgrade” and “when can I upgrade”, “when does my contract end” and “when is my contract ending”, and “live chat” & “live chats”. So, they would be counted together when aggregating by signature.
The procedure has its limitations and, as explained, it is experimental, so we are trying to improve it, but it can already alleviate a bit the inherent variability in user expressions.
AuraMsgGroup
Messages produced by Aura are as generated by its text resource database. In some cases, the same category of message produces different output texts, maybe because the message includes some user-dependent parameter or because the text database contains several variants of the same text (and Aura picks one at random).
The AuraMsgGroup field is a keyword field that helps categorize Aura answer by abstracting away some of this variation. It classifies the response given by Aura into two types of elements:
-
Generic group: a name such as <NONE>, <GREETING> or <NOTFOUND>, which corresponds to a response category (see Table 3)
-
Truncated answer: for answers that do not have a defined generic group, as a fallback the literal answer text is inserted, after substituting all numbers in it with a placeholder and truncating it (i.e., retain only the first characters).
The following table contains the generic groups defined so far. They correspond to the most frequent Aura messages. It is country-dependent, since it also depends on the use cases deployed in each country. As said above, responses not falling into these groups will be assigned a truncated version of the response text.
Note that th emost frequent Aura messages list can be enlarged with time. Also, the correspondence between Aura messages and groups is not static, if the text database is updated with new variants, it will be necessary to also update the translation table in the PPD cleaner process that generates this field.
| Group |
Meaning |
| EMPTY |
No textual answer from Aura (see note in Section MESSAGE_AURA for the usual meaning of no text answer) |
| NONE |
Aura says it did not understand the user utterance |
| ERR |
There was a processing error of some kind at Aura side, and the request could not be fulfilled |
| GREETING |
Aura is greeting the user |
| GOODBYE |
Aura is acknowledging a conversation end |
| YOU-ARE-WELCOME |
Aura is accepting a compliment |
| CHURN |
Aura recognizes the user intention to terminate a contract |
| NOTFOUND |
Aura tried to search for some bit of data concerning the user query, and could not find it |
| CANNOT |
Aura cannot fulfil the user request because of insufficient information (in the query, or on user data) |
| BILL-INFO |
The user requested information about her bill, and Aura is returning it |
| DATA-INFO |
The user requested information about her data usage, and Aura is returning it |
: The list can be enlarged with time. Also, the correspondence between Aura messages and groups is not static, if the text database is updated with new variants, it will be necessary to also update the translation table in the PPD cleaner process that generates this field.