RAG capability
Overview of the RAG capability, the benefits derived from its use and the current predefined RAG chain in ATRIA
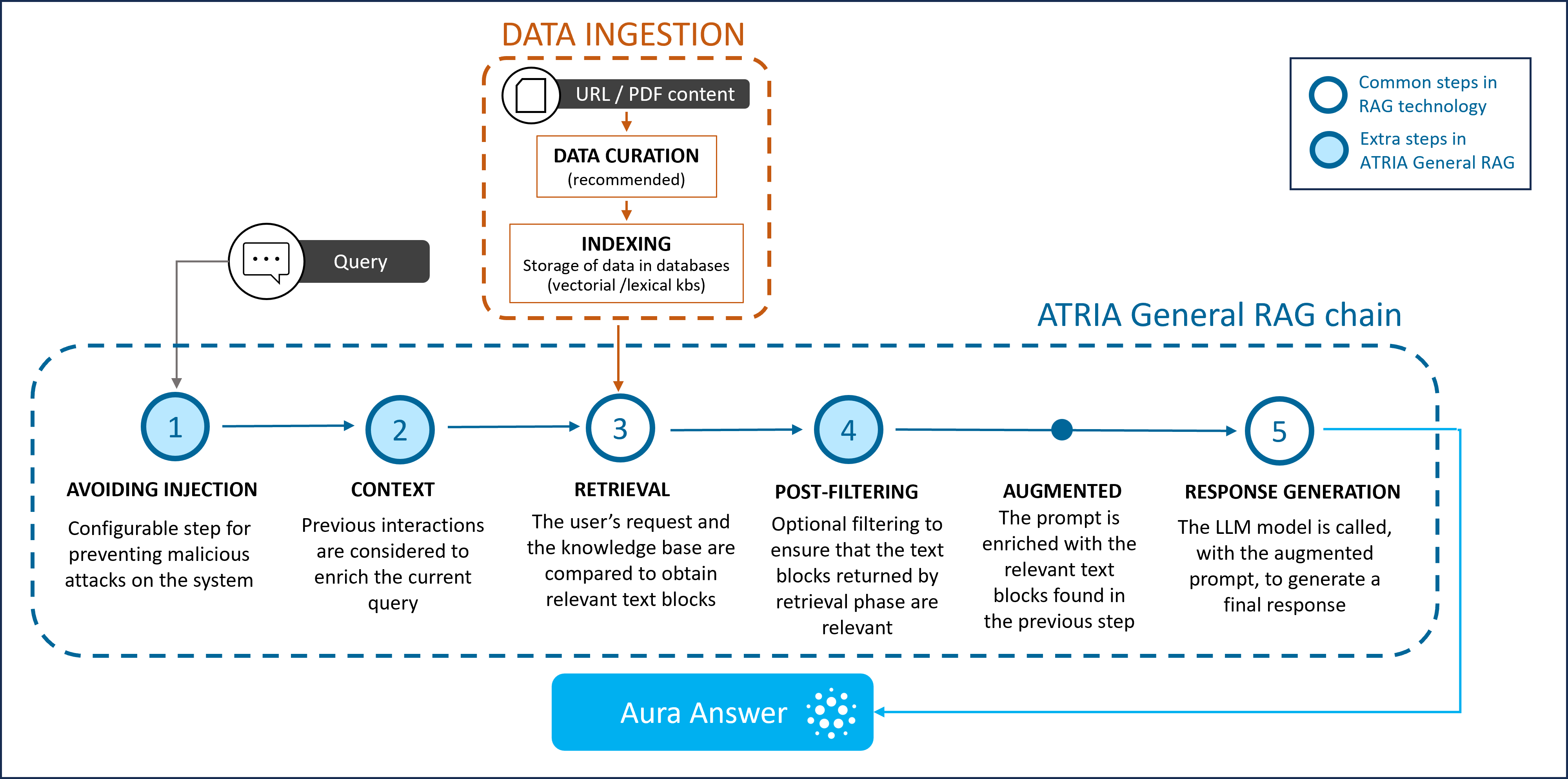
Introduction to RAG technology
RAG (Retrieval Augmented Generation) is a technique for augmenting LLM knowledge with additional data. It provides a way to optimize the output of an LLM with targeted and updated information without retraining it; thus, providing more appropriate answers based on specific and latest data.
The process includes three differentiated parts:
- Retrieval: it searches and extracts relevant information from a KB database using information retrieval techniques, such vector representations (embeddings) to find text blocks that contain the appropriate information to resolve the input request.
- Augmented: the RAG model augments the user input (or prompts) by adding the relevant retrieved data. This step uses prompt engineering techniques to communicate effectively with the LLM.
- Generation: the enriched prompt is sent to an LLM, that generates the most accurate response for the user.
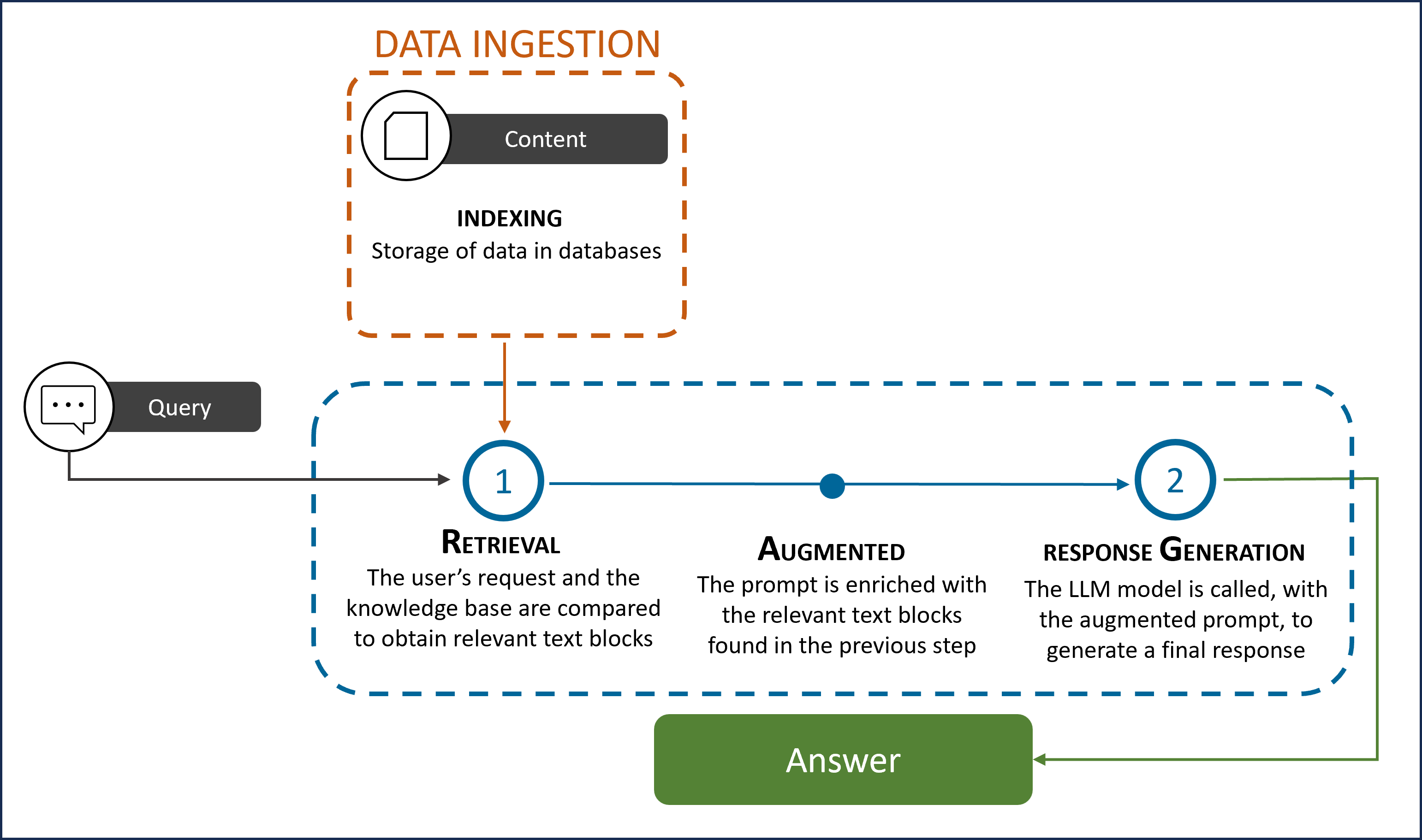
Figure 12. RAG technology
Application of RAG in ATRIA
As explained before, the LLM/LMM Experiences Builder enables the generation of LLM chains that integrate different AI technologies.
Within this capability, complex flows based on the RAG technology can be integrated.
Example case
Imagine that our platform, ATRIA, operates like a restaurant with different chefs, each specialized in a unique approach to meeting customers' needs.
A RAG model can be compared to Chef Sara, a chef who combines her traditional culinary experience with the real-time consultation of resources to enhance her recipes with the latest culinary trends worldwide, as she likes to be continuously up-to-date.
When a customer requests a nutritious and hearty meal, Sara goes beyond her own knowledge, based on already learnt techniques and recipes. Instead, she consults innovative cuisine resources: Indian cookbooks and her recent notes on advanced molecular cooking techniques. These external sources allow her to innovate and propose a unique dish: a curry foam, light and airy, with an intense spice flavor and a touch of coconut milk.
In technical terms, the RAG approach combines:
a. Generation based on prior knowledge (the internal model): equivalent to Sara's knowledge of cooking.
b. Real-time retrieval of external information: consulting cookbooks and notes represents how a RAG system looks up information in databases or dynamic sources during the response process.
This integration allows the model to provide more contextualized responses, tailored to specific needs, especially when the stored knowledge is limited or insufficient.
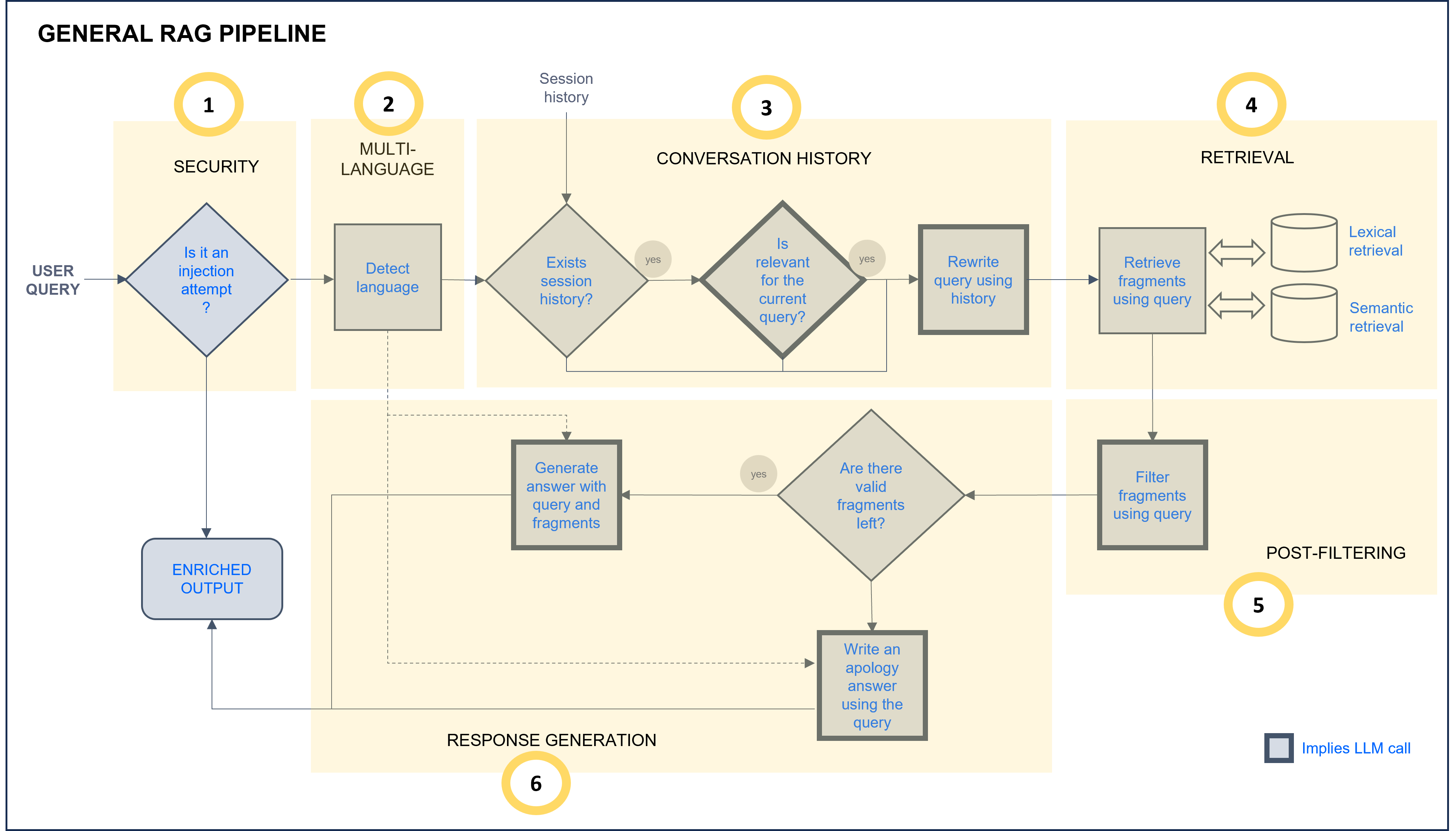
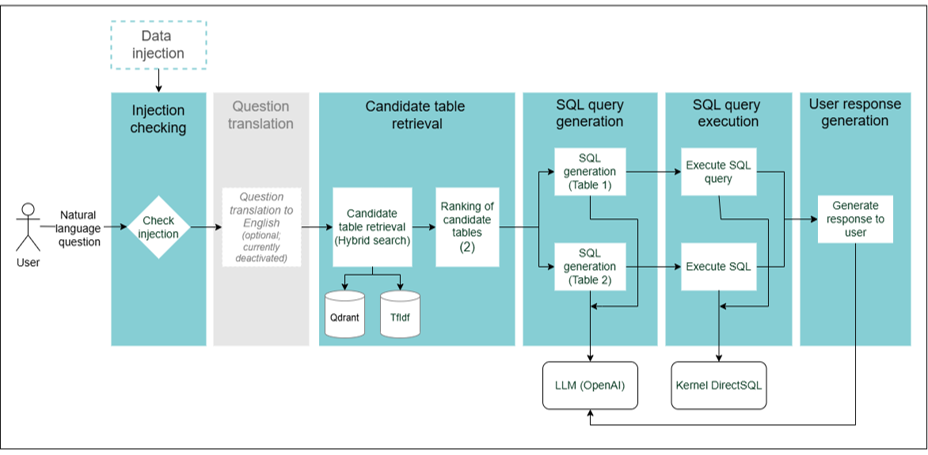
Currently, ATRIA incorporates the following RAG chains:
-
General RAG: Complex AI-driven flow for resolving generic questions experiences based on FAQs
-
SQL RAG: RAG-based pipeline for resolving SQL queries
In upcoming versions, constructors will be able to design their own LLMs chains based on RAG.
Benefits from the use of RAG technologies
-
Updated and targeted information: RAG allows developers to provide the latest data to the generative models, targeted to the specific use case.
-
Cost-effective implementation: Data in the knowledge repository can be continually updated without incurring significant costs.
-
Enhanced user trust: The data sources contributing to the RAG’s vector database are identifiable. This transparency allows for the correction or removal of any inaccuracies present in RAG and clearly improves users’ confidence.
-
Improved developers control: With RAG, developers can test and improve their applications more efficiently, control and change the LLM’s information sources to adapt to changing requirements, restrict sensitive information retrieval to different authorization levels and ensure the LLM generates appropriate responses.